Hi all,
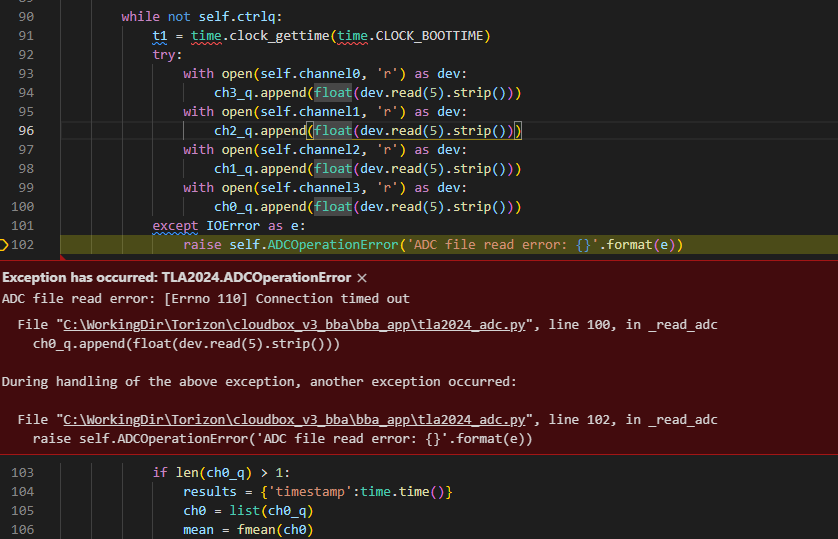
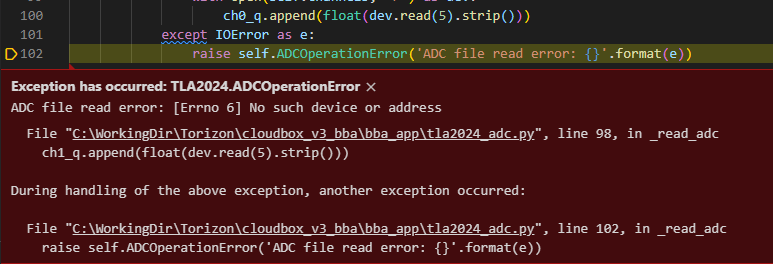
We have found a problem where the TLA2024 ADC on the Verdin IMX8MM throws exceptions occasionally. We read the device very regularly and it must be less than 1 in 10000 reads that fail. Originally I thought it was due to debugger detach/attach or some other testing related issue, however, we have now seen this happen on devices in the field.
At the moment the thread reading the ADC is monitored and restarted if it exits due to an exception so this is not a very big deal but it does seem like something is wrong somewhere.
I have attached the full version of the code used to read the device, it is not very special, just a thread and some surrounding functions to start/stop and handle locks. tla2024_adc.py (11.0 KB)
Hello @edwaugh, sorry for the delay in the answer.
I’ll try to simulate the problem on my side and try to find out what’s the reason for this issue. I saw in your exception reports that there are two different error returns (I assume they come from the read call).
It would be interesting to know if the error codes always vary or if they are limited to these two. It could be that there is some bus contention from time to time, and I would guess this could turn out to be a timeout error (like the one you showed).
It would also be interesting to know if there are error / log outputs coming from the syslog via dmesg.
Thanks Rafael, I will try to capture the dmesg log next time I see this error but it is quite hard to find. Any indication from the driver on under what conditions it might trigger this error? I don’t think the bus should be very busy, having to wait briefly for something else to use it would hopefully not cause this problem.
Hello @edwaugh, I tried to simulate the issue on my side but couldn’t replicate it. I made some quick changes to your script in order to be able to run it on my board directly (see attached). I added a sample counter so that I could see the amount of samples already taken as you mention that the problem probably happens less than once in 10000 samples.
I let the script run through the night and the counter reached upwards of 800000 samples and I did not see any issue.
This now brings some extra questions on my side:
Could you look at my modified script and check if I didn’t do anything wrong that would prevent me from seeing the same issue as you? I’m especially concerned that maybe I didn’t properly understand how to use the monitor_status call.
Have you seen this problem on all the hardware you have or only in some units?
Do you have other stuff running on the board while the sampling is going on?
Hi @rafael.tx,
Thanks very much for taking a look. We do have a lot of other stuff going on at the same time and there may even be rare moments of CPU limits.
Modifications look ok to me
I think on all units but it is a very low frequency occurrence so hard to be sure, in my post I mistyped, I think I mean less common than 1:100000
No need to use monitor status, this just lets another thread monitor this one for failure
One thing we do have is the alias to a different folder. @gauravks is there any reason why this might get updated and clash with the ADC read?
I have added some logging now so I could start to track how often it happens.
Thanks
Ed
I was performing some testing using a high CPU load loop as part of the application and noticed that the ADC problem occurs more frequently. Is there any timeout on a file read from Python? Perhaps you could try loading the processor in your test?
Sure thing, although this does just seem to be masking an underlying problem somewhere. I do think it is worth understanding it properly. Our devices need to run for very long periods unattended, ideally there wouldn’t be any race conditions like this (if that’s what it is).
hi @matthias.tx ,
I have updated TorizonCore image to latest v5.7 build24 and we have seen this issue with the ADC on a couple of the devices already after the OS update. A power cycle seems to make the ADC starting properly
Hello @edwaugh, @RoccoBr,
I started my test again, and now in parallel I’m running burn-a53 which loads all cpu cores 100%. I have more than 220000 reads executed and until now no error.
Because of this, I would like to ask: do you have a heatsink connected to your verdin module? I ask this because it could be that the dynamic change of cpu frequency could have an influence on the test results, something that is not happening on my test. With the heatsink the cpu temperature never goes above 66 degrees celsius, which is way below the 85 degrees that are necessary to trigger DVFS.
Hi @rafael.tx,
We do not see any overheating in the loading test, I suspect the difference could be that my application is both performing the reads and running the CPU test on a single python thread as this is what we care about. I think that will be quite different to Linux managing multiple processes. Perhaps this gives us a clue that the race condition is inside Python somewhere.
Perhaps we can come back to look at this as part of our next release as we also see the adc not starting sometimes. Do you ever see that behaviour?
Thanks
Ed
Hi @edwaugh,
How are you making sure that both the python application and cpu test run on the same cpu? Are you setting up cpu affinity for these tasks?
Do you have a specific reason for doing that?
Apart from the test running on the same cpu, the only thing I can think at the moment that could be different is the temperature of the cpu. Do you reproduce the issue when the cpu is at a temperature similar to the one on my tests (never surpassing 85 degrees)?
I started the ADC test on my end 5 days ago and it’s still running strong. At the moment I have more than 5500000 samples taken.
Hi @rafael.tx,
Thanks for going to so much effort to explore this.
The cpu test and adc read happen as part of the same python application. This means they are in the same process and only run on one CPU. If you want to use multiple processes with python you need to create them explicitly with the multiprocessing library. I think having them both in the same application does a better job of replicating the performance on the device as all our processing is also in the same application.
You could try adding the CPU test to your ADC reading script. I have attached the code I use to do this, should be straighforward for you to call it hopefully, I have included the only dependency.
Just create an instance of the IMX8MMFeatures class and call cpu_memory_start and a thread. Just need to call stop to stop it again.
Thanks
Ed cpu_test.zip (3.6 KB)