Hello @TobiasAtAGI,
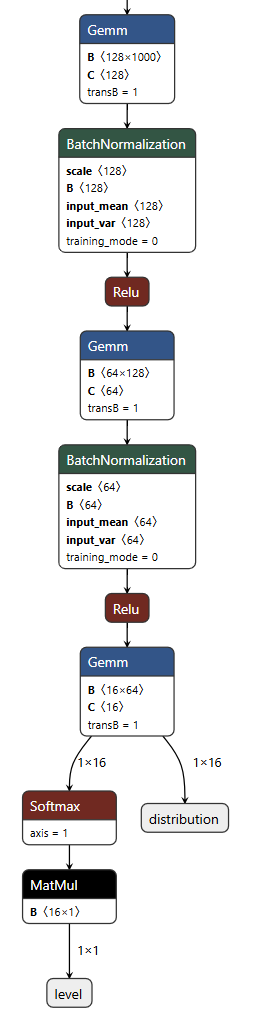
Thanks for sending your tflite models. After analysing one of them in Netron, it looks like it is correctly quantized. So I would say, your conversion from Pytorch to tflite model looks correct/good.
Now, regarding converting the model with neutron-converter: As you figured out, this step is not necessary for the BSP version 6.6 (I believe for BSP >= 6.6.52). Therefore, it is not needed on the version you have - which is 6.6.101. I tested the standard mobilenet model in the examples directory, both on CPU and NPU delegation, without any neutron conversion on a Verdin iMX95 module running Toradex BSP 7.4.0 with 6.6.94 kernel, and that worked fine.
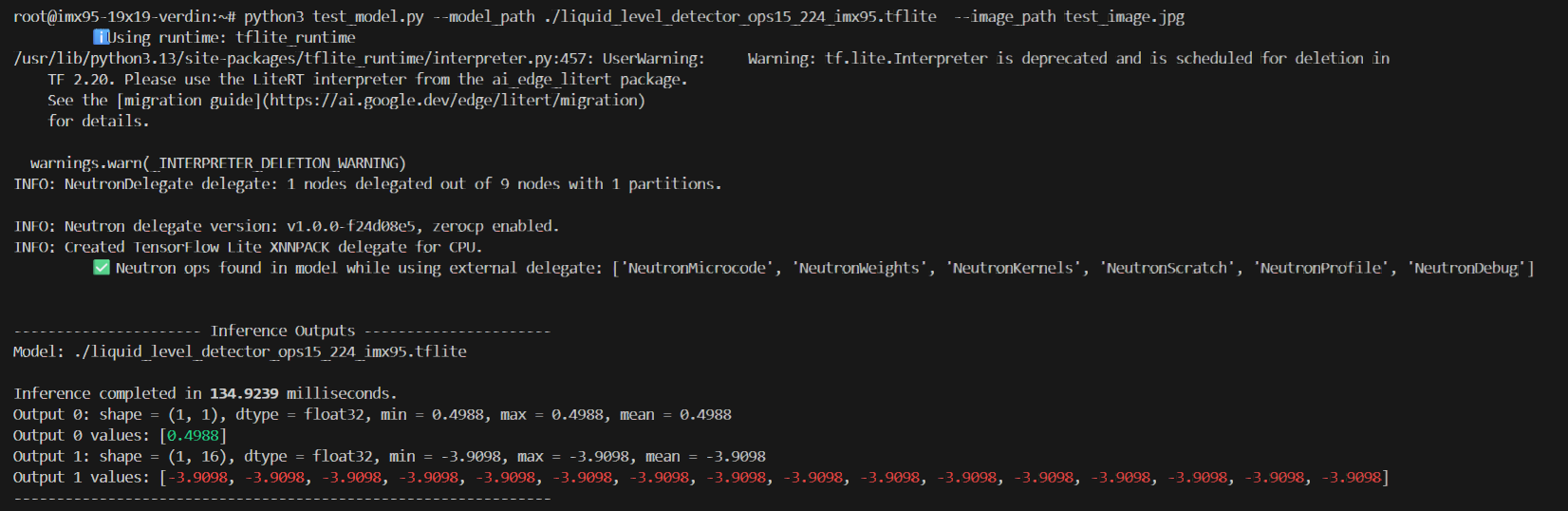
Testing your tflite model on the above-mentioned BSP version on a Verdin iMX95 SoM, with neutron delegation, I see the same “Out of TCM memory!” warning message printed out. I tried to convert the model with the Neutron converter in eIQ SDK 1.14 ( /opt/nxp/eIQ_Toolkit_v1.14.0/neutron-tuning/neutron-converter, which is supposed to work for NXP BSP 6.6.52), I get a warning message “WARNING: None of the operators from graph is supported by Neutron!”:
rudhi@rudhi-nb:/opt/nxp/eIQ_Toolkit_v1.14.0/neutron-tuning$ ./neutron-converter --input lld_ops15_224.tflite --output lld_ops15_224_neutron.tflite --target imx95 --dump-statistics
WARNING: Deltas for subsystem are deactivated for now.
Converting model with the following options:
Input = lld_ops15_224.tflite
Output = lld_ops15_224_neutron.tflite
Target = imx95
WARNING: De-extracting subgraph 'subgraph_031' because of a failure!
======================================================== Model: ========================================================
Performance estimates:
Clock Frequency: 0.00 MHz
Clock cycles per inference: 0
Latency per inference: -nan ms
Inferences per second: -nan
Memory footprint:
Variables size: 0.000000 MB
Constants size: 0.000000 MB
Microcode size: 0.000000 MB
Conversion statistics:
Number of operators after import = 44
Number of operators after optimize = 57
Number of operators converted = 0
Number of operators NOT converted = 57
Number of operators after extract = 57
Number of Neutron graphs = 0
Number of operators NOT converted = 57
Operator conversion ratio = 0 / 57 = 0
WARNING: None of the operators from the graph is supported by Neutron!
Time for optimization = 0.0183315 (seconds)
Time for extraction = 0.00630146 (seconds)
Time for generation = 0.936474 (seconds)
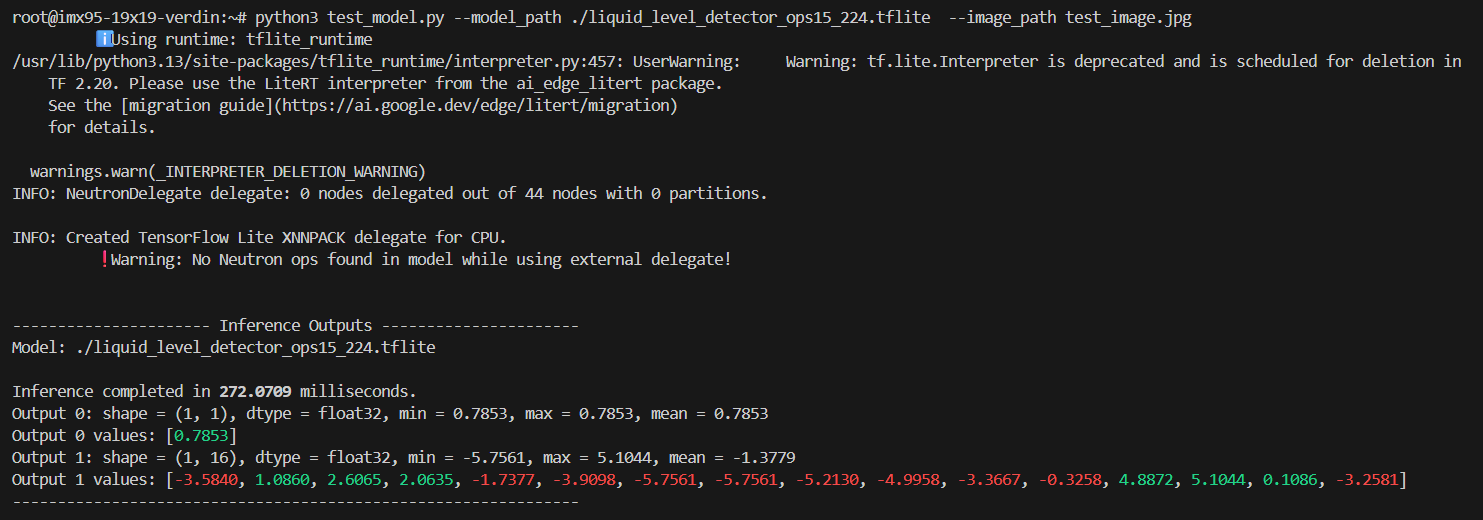
This gives me the indication that your model (specifically the operators) is not supported by this BSP version. So I tried to run your model on a higher BSP version from NXP, which is 6.12 Walnascar. However, we do not have a Walnascar BSP from Toradex for Verdin iMX95 yet. Therefore, I have to rely on the NXP BSP and the Verdin iMX95 EVK. I can see some promising results there. The model needs to be converted with neutron-converter in a compatible eIQ SDK version (I used SDK 2.2.3), for the NPU delegations to work:
I converted the model with eIQ SDK 2.2.3:
rudhi@rudhi-nb:~/Toradex/ML_Projects/eiq-neutron-sdk-linux-2.2.3-ext/eiq-neutron-sdk-linux-2.2.3/bin$ ./neutron-converter --input lld_ops15_224.tflite --output lld_ops15_224_neutron.tflite --target imx95 --dump-statistics
Infer on CPU:
root@imx95-19x19-verdin:/usr/bin/tensorflow-lite-2.19.0/examples# ./label_image -m lld_ops15_224.tflite -i grace_hopper.bmp -l labels.txt
INFO: Loaded model lld_ops15_224.tflite
INFO: resolved reporter
INFO: Created TensorFlow Lite XNNPACK delegate for CPU.
INFO: invoked
INFO: average time: 32.53 ms
INFO: 0.565003: 0 background
Infer on NPU (model converted with SDK 2.2.3 as mentioned above):
root@imx95-19x19-verdin:/usr/bin/tensorflow-lite-2.19.0/examples# ./label_image -m lld_ops15_224_neutron.tflite -i grace_hopper.bmp -l labels.txt --external_delegate_path=/usr/lib/libneutron_delegate.so
INFO: Loaded model lld_ops15_224_neutron.tflite
INFO: resolved reporter
INFO: EXTERNAL delegate created.
INFO: NeutronDelegate delegate: 1 nodes delegated out of 9 nodes with 1 partitions.
INFO: Neutron delegate version: v1.0.0-d98743a7, zerocp enabled.
INFO: Applied EXTERNAL delegate.
INFO: Created TensorFlow Lite XNNPACK delegate for CPU.
INFO: invoked
INFO: average time: 0.249 ms
INFO: 0.500431: 0 background
Infer on NPU with the default NON-converted model:
root@imx95-19x19-verdin:/usr/bin/tensorflow-lite-2.19.0/examples# ./label_image -m lld_ops15_224.tflite -i grace_hopper.bmp -l labels.txt --external_delegate_path=/usr/lib/libneutron_delegate.so
INFO: Loaded model lld_ops15_224.tflite
INFO: resolved reporter
INFO: EXTERNAL delegate created.
INFO: NeutronDelegate delegate: 0 nodes delegated out of 44 nodes with 0 partitions.
INFO: Applied EXTERNAL delegate.
INFO: Created TensorFlow Lite XNNPACK delegate for CPU.
INFO: invoked
INFO: average time: 32.48 ms
INFO: 0.565003: 0 background
Looking at the average time printed out in the output, it is clear that the converted model is getting delegated correctly to the NPU.
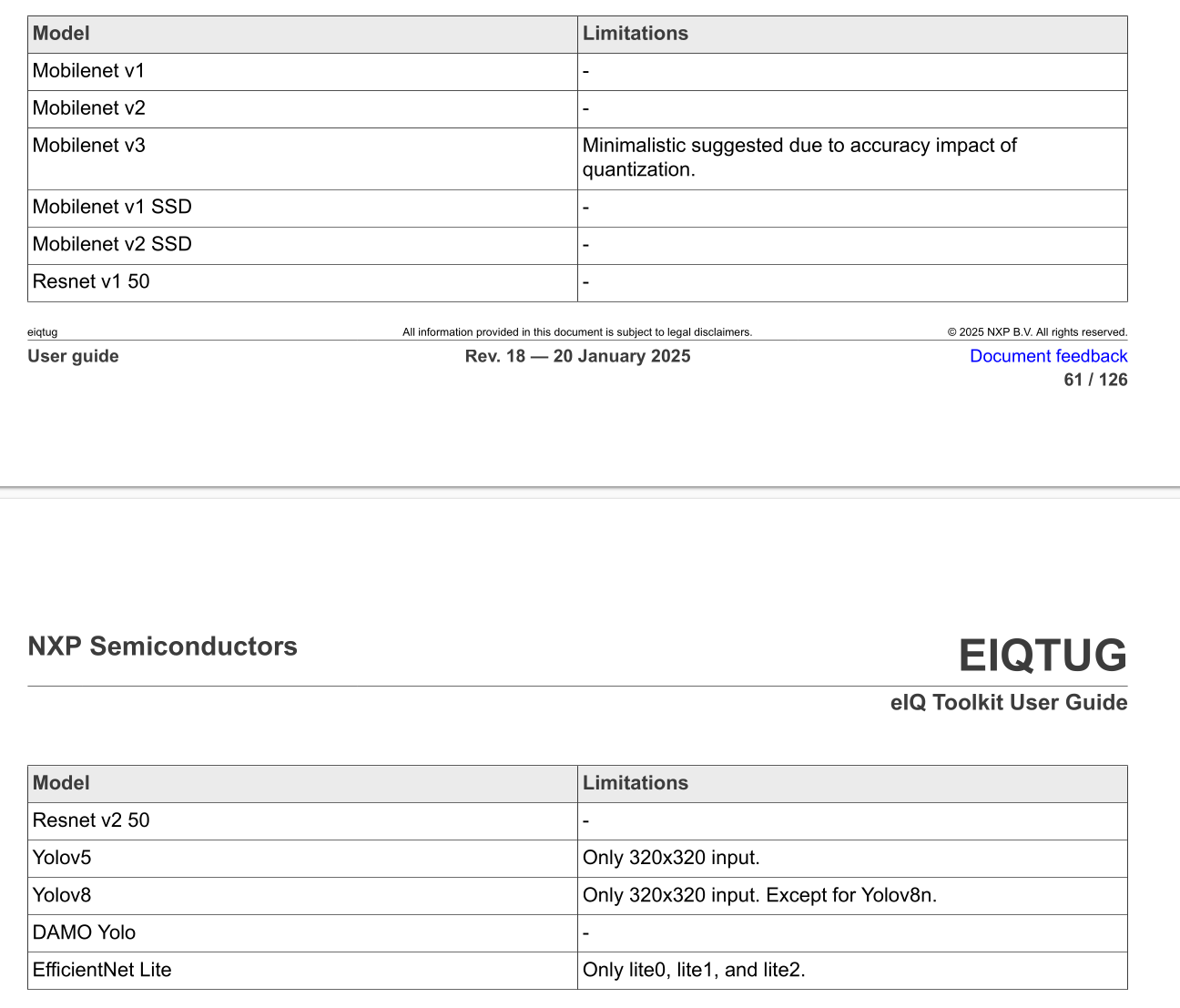
I think if you really want to get this model working on BSP with kernel 6.6, you need to use a backbone model that enables the neutron optimizations. In the eIQ Toolkit UserGuide that comes with eIQ 1.14 version (which they say is supported by BSP 6.6.52), I see the following list of models with such optimizations enabled:
Not sure if you are already using one of these models.
Otherwise, the option would be to wait until Toradex releases a Walnascar BSP image for Verdin iMX95, which should be sometime soon.