Hello,
I am working on an RTSP streaming application running on a Toradex Verdin i.MX8MP module using the NXP Yocto BSP (imx-gpu-viv for EGL).
The application uses GStreamer with the NXP hardware-accelerated pipeline (vpuenc_h264) to serve multiple H.264 streams via gst-rtsp-server.
Issue:
When two or more RTSP clients are connected and two disconnect (one after the other), the application crashes inside eglTerminate() while tearing down the pipeline.
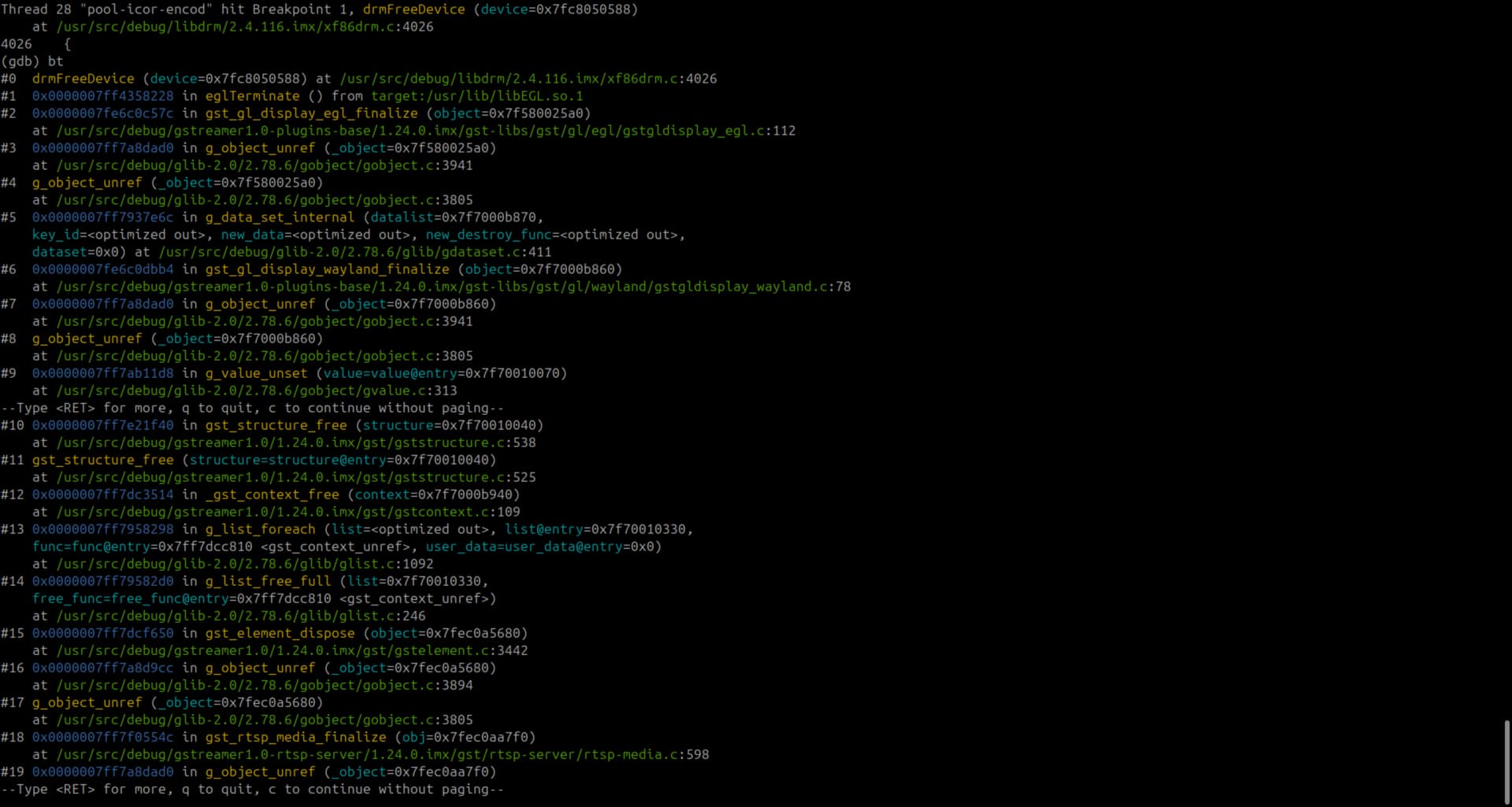
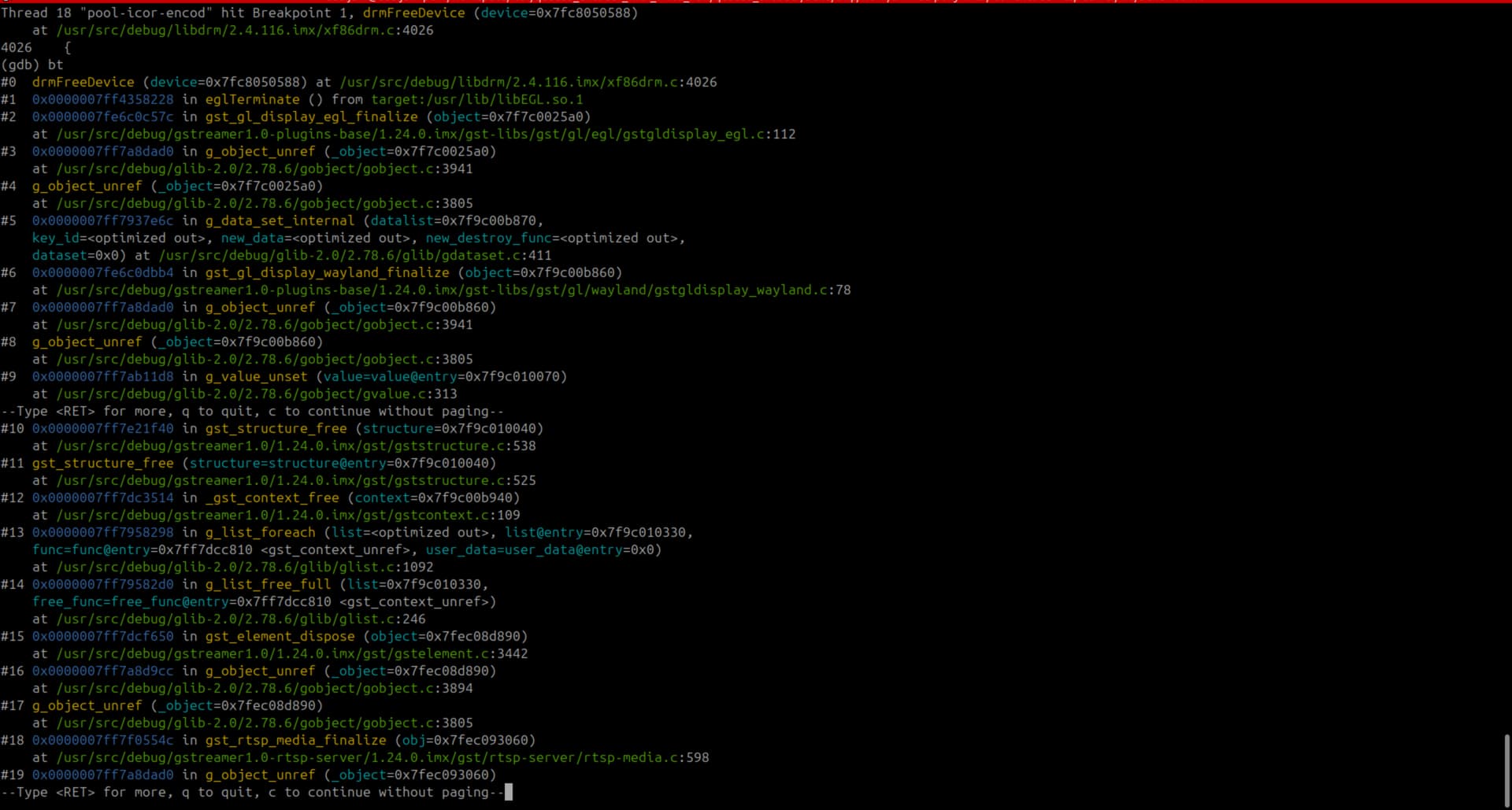
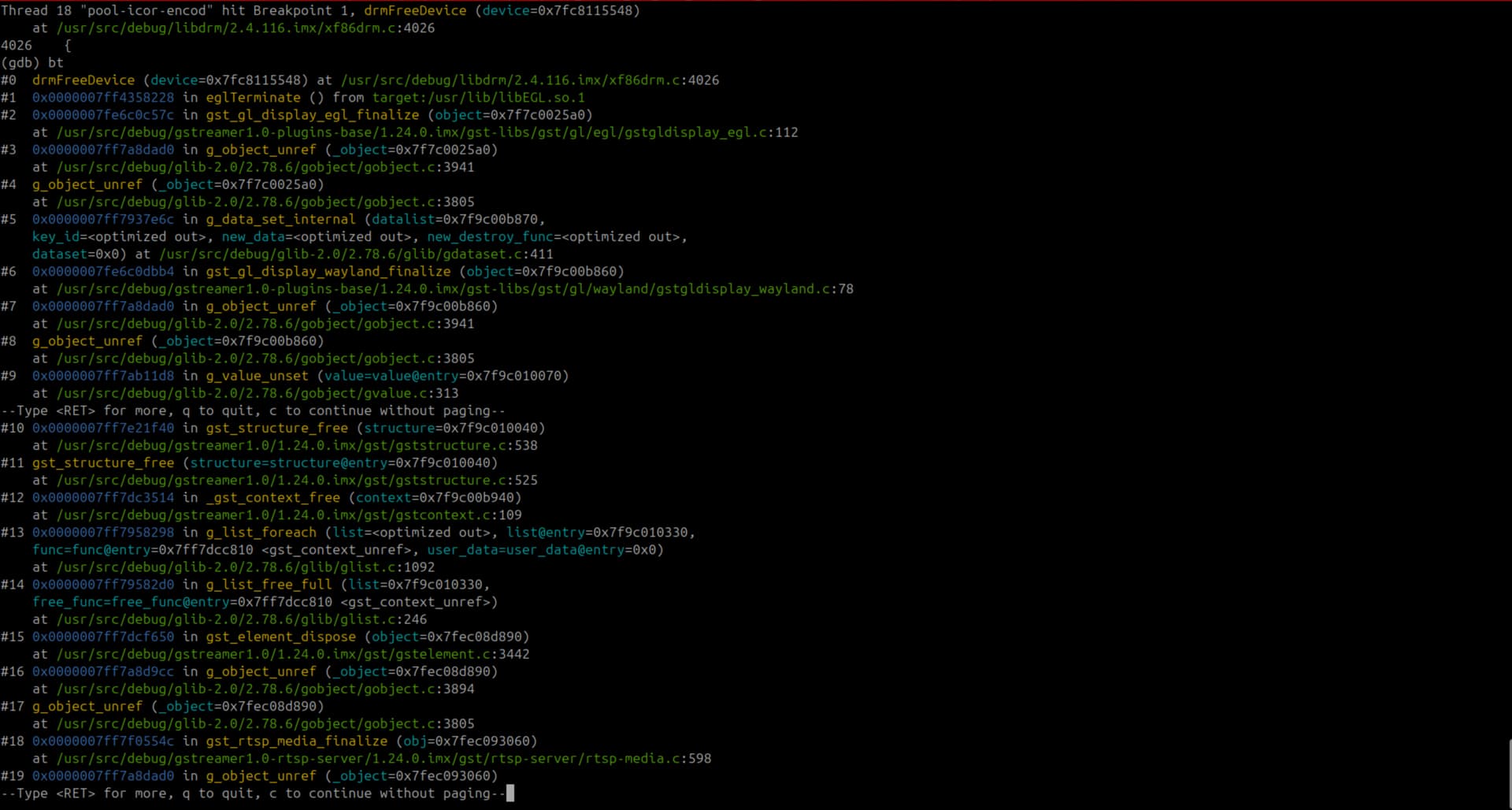
The backtrace shows that the crash happens inside drmFreeDevice() in libdrm, which is called indirectly from eglTerminate().
In GDB, the device pointer in drmFreeDevice sometimes contains a small integer value (e.g., 0x21) instead of a valid pointer, which triggers an invalid memory access.
The crash only occurs when using gldeinterlace (OpenGL-based deinterlacing) in the pipeline with glupload and gldownload. If I switch to CPU-based deinterlacing (deinterlace element), the crash does not happen. It uses DMABuf.
The application uses 4 cameras, and one client connects to one stream. 2 clients cannot connect to the same camera stream.
It seems to be related to GstGLDisplayEGL. This suggests that eglTerminate is being called with an already-freed or corrupted DRM device pointer, possibly due to improper cleanup of GPU resources in multi-stream scenarios.
In the images, you can see the backtrace for 2 clients disconnecting:
- First client disconnects and there is one call for drmFreeDevice
- Second client disconnects and there are 2 calls for drmFreeDevice
Summary of output from tdx-info:
Software summary
Bootloader: U-Boot
Kernel version: 6.6.84-0 #1 SMP PREEMPT Mon Mar 31 08:47:48 UTC 2025