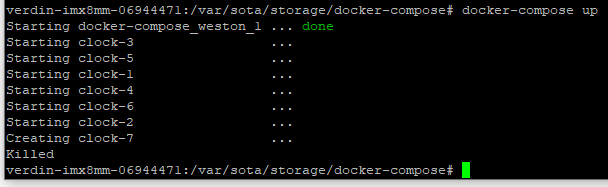
hi @seasoned_geek
Thanks for following up on this. I ran your commands and here are the results:
verdin-imx8mm-06944471:~$ ulimit -Sa
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 2835
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 2835
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
stack size might be a bit low, but it wouldn’t explain why the container type doesn’t matter. Heavy, light or mixed, I always get to 8.
verdin-imx8mm-06944471:~$ ulimit -Ha
core file size (blocks, -c) unlimited
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 2835
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 524288
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) unlimited
cpu time (seconds, -t) unlimited
max user processes (-u) 2835
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
Pipe size: 8. Could that be the issue?
verdin-imx8mm-06944471:~$ docker info
Client:
Debug Mode: false
Server:
Containers: 3
Running: 3
Paused: 0
Stopped: 0
Images: 3
Server Version: 19.03.14-ce
Storage Driver: overlay2
Backing Filesystem: extfs
Supports d_type: true
Native Overlay Diff: true
Logging Driver: journald
Cgroup Driver: cgroupfs
Plugins:
Volume: local
Network: bridge host ipvlan macvlan null overlay
Log: awslogs fluentd gcplogs gelf journald json-file local logentries splunk syslog
Swarm: inactive
Runtimes: runc
Default Runtime: runc
Init Binary: docker-init
containerd version: 3b3e9d5f62a114153829f9fbe2781d27b0a2ddac.m
runc version: 425e105d5a03fabd737a126ad93d62a9eeede87f-dirty
init version: fec3683-dirty (expected: fec3683b971d9)
Security Options:
seccomp
Profile: default
Kernel Version: 5.4.161-5.6.0+git.0f0011824921
Operating System: TorizonCore 5.6.0+build.13 (dunfell)
OSType: linux
Architecture: aarch64
CPUs: 2
Total Memory: 977.4MiB
Name: verdin-imx8mm-06944471
ID: 6KGF:FJUR:7TJ6:5QNO:HP75:GBVB:7UFX:O6UJ:R5IT:RCVP:7YN6:WTQR
Docker Root Dir: /var/lib/docker
Debug Mode: false
Registry: https://index.docker.io/v1/
Labels:
Experimental: false
Insecure Registries:
127.0.0.0/8
Live Restore Enabled: false
verdin-imx8mm-06944471:~$
2 CPUs, but I don’t think that is as relevant to docker as it is to VMs. Docker is not a full hypervisor and I think containers can share CPU-time.
Just to be clear, I’m not running 8 webservers  That was just an example to illustrate the issue. My application consists of 8 completely different containers, most of which are really lightweight. I’m afraid you’re right though, and I’ll need to merge some to get the number under 8 unless this thread rings a bell at Toradex support.
That was just an example to illustrate the issue. My application consists of 8 completely different containers, most of which are really lightweight. I’m afraid you’re right though, and I’ll need to merge some to get the number under 8 unless this thread rings a bell at Toradex support.