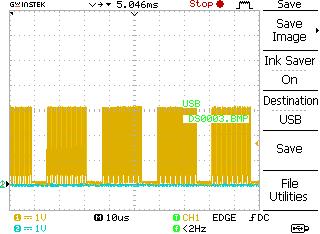
We are using Colibri iMX6 with Angstrom ToradexLinux 2.7 and “spidev” SPI driver. The issue appear also with the standard spidev_test example application of the spidev driver when you send more than 16bytes. We use it in our application the same way as in spidev_test example with " ioctl(fd, SPI_IOC_MESSAGE(1), &tr);" and the same settings
That’s the portion of the code:
static const char *device = "/dev/spidev3.0";
static uint8_t mode;
static uint8_t bits = 8;
static uint32_t speed = 20000000;
static uint16_t delay;
static void transfer(int fd) { //unsigned long cnt = 1000; int ret;
//uint8_t tx[] = {}
uint8_t rx[ARRAY_SIZE(tx)] = {0, };
struct spi_ioc_transfer tr = {
.tx_buf = (unsigned long)tx,
.rx_buf = (unsigned long)rx,
.len = ARRAY_SIZE(tx),
.delay_usecs = delay,
.speed_hz = speed,
.bits_per_word = bits,
};
ret = ioctl(fd, SPI_IOC_MESSAGE(1), &tr);
if (ret < 1)
pabort("can't send spi message");
}
Where actually the commented //uint8_t tx[] = {} array to be transfered is declared externally in .h file simply with long array pattern to generate dummy transfers to the ADC spi in order to get data out of it:
const uint8_t tx[] = { 0x80, 0x00, 0x00, 0x80, 0x00, 0x00, /KPE/ 0x80, 0x00, 0x00, 0x80, 0x00, 0x00, /KPE/ 0x80, 0x00, 0x00, 0x80, 0x00, 0x00, /KPE/ 0x80, 0x00, 0x00, 0x80, 0x00, 0x00, /KPE/ 0x80, 0x00, 0x00, 0x80, 0x00, 0x00, /KPE/ 0x80, 0x00, 0x00, 0x80, 0x00, 0x00, /KPE/ 0x80, 0x00, 0x00, 0x80, 0x00, 0x00, /KPE/ 0x80, 0x00, 0x00, 0x80, 0x00, 0x00, /KPE/ 0x80, 0x00, 0x00, 0x80, 0x00, 0x00, /KPE/ 0x80, 0x00, 0x00, 0x80, 0x00, 0x00, /KPE/ 0x80, 0x00, 0x00, 0x80, 0x00, 0x00, /KPE/ 0x80, 0x00, 0x00, 0x80, 0x00, 0x00, /KPE/ 0x80, 0x00, 0x00, 0x80, 0x00, 0x00, /KPE/ 0x80, 0x00, 0x00, 0x80, 0x00, 0x00, /KPE/ 0x80, 0x00, 0x00, 0x80, 0x00, 0x00, /KPE/ 0x80, 0x00, 0x00, 0x80, 0x00, 0x00, /KPE/ 0x80, 0x00, 0x00, 0x80, 0x00, 0x00, /KPE/ 0x80, 0x00, 0x00, 0x80, 0x00, 0x00, /KPE/ 0x80, 0x00, 0x00, 0x80, 0x00, 0x00, /KPE/ 0x80, 0x00, 0x00, 0x80, 0x00, 0x00, /KPE/ ...................... // and so on... long pattern... }