Hello!
We’re adding support for indian languages of Hindi and Tamil. The application runs on Colibri T30 using .NET CF 2.0.
In process we encountered the following issue that some characters are displayed differently in the MSVS designer and in the target device. The designer displays all correctly, but the device wraps some symbols and other ones are swapped. All displays correctly if the assembly is running on PC.
We’ve tried two TTF fonts: Rozha One and Arial Unicode MS. The font style is changed of course but the issue persists.
The fonts are installed using AutoCopy feature:
\flashdisk\autocopy\windows\fonts\rozhaone.ttf
\flashdisk\autocopy\windows\id.nlx
\flashdisk\autocopy\windows\wince.nls
Application uses an Indonesian locale because the Hindi seems to be missing:
[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\ExtendedLocale]
“id-ID”=“id-ID”
[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\ExtendedLocale]
“id”=“id”
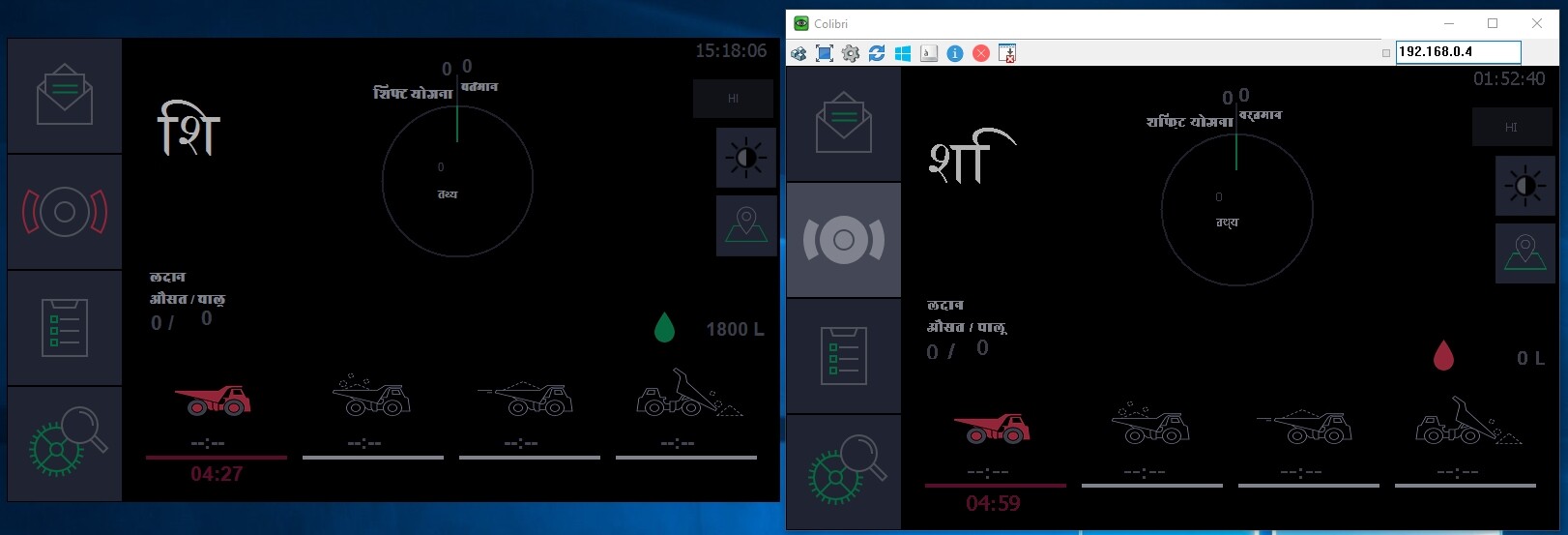
For example, please check the screenshot. On left - the assembly running on PC, on right - the assembly running on Colibri:
Hi,
Can you try with these files
Download hi.nlx from here
[1]: https://share.toradex.com/a2ubwl6i5humw6t?direct
Registry settings
[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\ExtendedLocale]
"hi-IN"="hi-IN"
[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\ExtendedLocale]
"hi"="hi"
We’ve installed these files and registry keys, and changed the localization to HI in the applicaton. This causes an exception in the application:
at System.Globalization.CultureInfo..ctor()
at System.Globalization.CultureInfo.GetCultureInfoHelper()
at System.Globalization.CultureInfo.GetCultureInfo()
at System.Globalization.CompareInfo.GetSortingLCID()
at System.Globalization.CompareInfo..ctor()
at System.Globalization.CompareInfo.GetCompareInfo()
at System.Globalization.CultureInfo.get_CompareInfo()
at System.Globalization.CultureInfo.GetHashCode()
at System.Collections.Hashtable.GetHash()
at System.Collections.Hashtable.InitHash()
at System.Collections.Hashtable.get_Item()
at System.Resources.ResourceManager.InternalGetResourceSet()
at System.Resources.ResourceManager.GetObject()
at System.Resources.ResourceManager.GetObject()
at TruckBoard.FormTruckBoard.InitializeComponent()
at TruckBoard.FormTruckBoard..ctor()
at TruckBoard.Program.SafeMain()
at TruckBoard.Program.Main()
Installed HI locale is not found in the control panel also.
We use wince.nls from https://docs.toradex.com/106017-addlocales.zip installed by method #1 from here: Add locales to an existing Windows Embedded Compact image | Toradex Developer Center
BTW, recently we have localized the issue a bit. It’s related to so called Unicode Combining Characters. The simple characters are displayed correctly on Colibri, but complicated ones (that are assembled of a character and a unicode combining mark from Devanagari Unicode Block U+090x) are displayed wrong.
As a result, it looks very likely that there is a problem in rendering Unicode fonts in the current WinCE 7.0 build. I would like you to either confirm or refute our conclusion. As a workaround, we had to switch to a non-Unicode font.
Allow me some more time to look into it. It does not seem to be working at my end also. You mentioned that you switched to non-Unicode font, is that working as required?
Yes, this problem is not observed when using a non-Unicode font. However, there are also some undesirable effects that need to be avoided. They are related to the fact that we still use simultaneously a Unicode font for the Tamil language in the same application. Therefore, a Unicode solution would be preferable.
Please, also check this information from: https://www.ashtangayoga.info/philosophie/sanskrit-und-devanagari/fonts-schriften-fuer-devanagari-und-lautschrift-iso-15919/sanskrit-/-devanagari-problem-solving/
Incorrect consonant identification and rotated vowels:
Problem:
Devanagari (देवनागरी, Devanāgarī) symbols are displayed, but the identification (link) is wrong and some letters are mixed up. Vowels for instance are always displayed to the right of the corresponding consonant. This problem usually only occurs in FireFox and not in Internet Explorer.
Cause:
There appears to be insufficient support of complex typefaces in your operating system (Complex script support). Internet Explorer usually doesn’t have this problem, as it uses a “Uniscribe Engine” which isn’t available to other operating systems.
Solution:
In order to be able to read Devanagari (देवनागरी, Devanāgarī) correctly in the whole operating system, install the complex script support in your operating system
How do we install this script support into WinCE 7?
Hi,
I don’t know if its really a problem or not.
I tested “Hindi fonts” with a C code and here are my observations when I tried to print
"हिंदी भाषा का उधारण"
What seems to be happening here is when you write हिंदी, there are 5 characters involved in it.
"ि" "ह" "॑" "द" " ी"
and the actual sequence for writing this in Hindi
"ह" "ि" "॑" "द" " ी" .
You first write “ह” and then use this “ि” to make ह + "ि = हि.
I tested this with the character map also which is available on my windows PC. Try writing हि and you will get to know the sequence of it.
[upload|dcmJUzZcY6cDAtCqlDrO4CBBvv0=]
The same thing seems to be happening on your application side.
I tested with this code and this is my output
.[upload|k/wUUwwiFdPz4VXDqppynzhw8rU=]
You can see the difference between the first two lines.
As a workaround, I used the Unicode numbers to print in the correct sequence in the second line
So, this - \u093F\u0939\u0951\u0926\u0940 \u092D\u093E\u0937\u093E \u0915\u093E \u0909\u0918\u0930\u0923 \u0964
printed to - “हिंदी भाषा का उधारण” which is the correct sequence.
I don’t have any c# sample application to test with. Let me know if this helps
So you suggest changing the order of certain letters from Devanagari Unicode block before displaying them on the screen? But what happens if two such special letters stand in a row. For example, this situation is shown in the screenshot at the beginning of the topic. In theory, all these situations should be solved automatically by supporting complex scripts. In addition, our application must output not only static text, but also text loaded from XML and text that comes over the radio channel from the server.
I’m not sure that workaround will work correctly in all cases.
I sent the C# code by the e-mail.
Hi @protasovdg,
Try to display Hindi characters using Unicode. eg
शिव = ि + श + व = \u093F\u0936 \u0935
शनि = श + ि + न = \u0936\u093F\u0929
Let me know your inputs on this
No good so far.
On PC:
[upload|fBxrcJ/gBiWNzQ2j2UZ47gP7804=]
On Colibri:
[upload|zUbREJhEhG1IkH/FkOl2xA7hxQo=]
Piece of code:
Form1 f = new Form1();
IntPtr h = f.Handle;
f.BeginInvoke(
(Action)delegate()
{ f.label2.Text = “\u093F\u0936\u0935 \u0936\u093F\u0929”; });
Hi, @sahil.tx!
As a result, after further study of the problem, I realized that there is no way to solve it without modifying the OS image. This is because the customer wants to not only output text in Hindi and Tamil, but also input.
As far as I understand, this will require adding the following internalization components to the image: keyboard, font, locale, and Unicode script processor, both for Hindi and Tamil. Probably more, maybe I’m missing something.
Tell me please, can we order the build of such an image (WEC7 for Colibri T30) and how many hours of support will it cost?
Perfect that the issue is solved. Thanks for the feedback.