Dear Toradex Support Team,
We are conducting inference using MobileNetV2 (keras → TFLite) on i.MX95 and have observed significant differences in NPU assignment depending on input resolution. We are writing to confirm whether this is a specification constraint or an issue.
Observed Phenomenon
When using MobileNetV2:
At 224×224 input resolution:
-
NPU conversion proceeds without issues
-
High NPU convert ratio (121/127 operators)
-
Short inference time (CPU: 37.21ms → NPU: 3.17ms)
At 320×320 or higher input resolution:
-
NPU convert ratio decreases significantly (many operators fall back to CPU execution)
-
Inference time increases dramatically as a result (CPU: 76.08ms → NPU: 87.38ms)
We confirmed the above differences when only changing the resolution with the same model architecture. (We also observed the same phenomenon with ResNet50V2, indicating this is not model-specific.)
Detailed experimental environment, inference times, and conversion results are shown below.
■ Experimental Environment
| Item | Details |
|---|---|
| BSP | 6.6.36_2.1.0 |
| eIQ Toolkit | 1.16.0 |
| Model | MobileNet_v2 (tf.keras) |
| Conversion Method | tensorflow.lite.TFLiteConverter (2.15.0) |
| Quantization Method | Static quantization, INT8 (Per-channel) |
| Calibration Data | ImageNet-V2, 100 samples |
■ Results Comparison by Resolution
| Metric | 224×224 | 320×320 | Ratio Change |
|---|---|---|---|
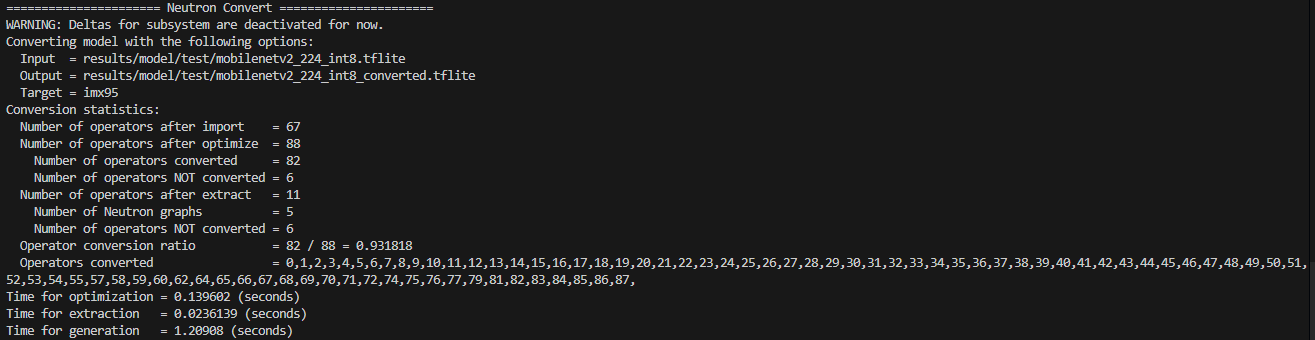
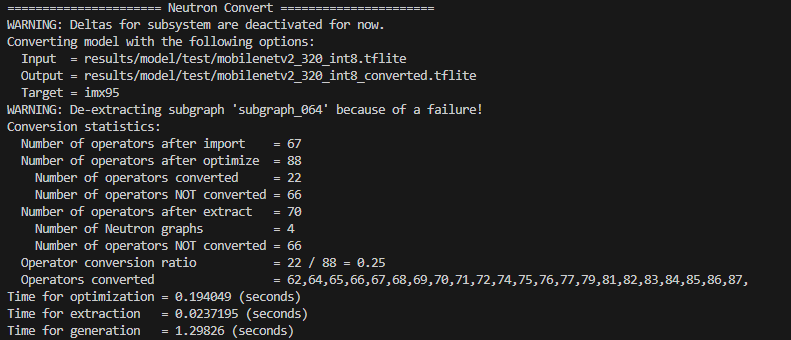
| Operator Conversion Ratio | 82/88 (93.2%) | 22/88 (25.0%) | -73.2% |
| Inference Time (CPU) | 37.21 ms | 76.08 ms | ×2.04 |
| Inference Time (NPU) | 3.17 ms | 87.38 ms | ×27.6 |
| NPU Speedup vs CPU | 11.7× faster | 1.15× slower | Performance reversal |
Key Observations:
-
NPU conversion ratio drops dramatically from 93% to 25%
-
NPU inference time increases 27.6×, far exceeding the theoretical 2.04× based on resolution increase
-
At 320×320, NPU becomes slower than CPU, defeating the purpose of hardware acceleration
■ Neutron Convert log(CLI)
At 320×320, only operators near the output layer are converted to NPU**, while early and intermediate layers fall back to CPU execution
224x224
320x320
Questions
Q1. Are there any upper limits or constraints on input resolution or intermediate tensor sizes for the i.MX95 NPU?
For example:
-
Maximum feature map size (width × height × channels)
-
Total number of elements in convolution input/output tensors
-
Memory bandwidth or internal SRAM block constraints
-
Other undocumented limitations
Q2. Is it possible for specific layers to become NPU-incompatible when resolution increases?
For instance:
-
At 224×224: A certain layer can be assigned to NPU
-
At 320×320: The same layer falls back to CPU execution
Q3. Is this behavior due to undocumented internal specifications or a known issue?
We could not find such constraints in the current documentation. We would like to confirm whether:
-
Unpublished internal specification constraints exist
-
This is a known bug or limitation in BSP 6.6.36_2.1.0
-
There are any workarounds or recommended settings