Hi Henrique, sorry I didn’t realise:
The previous application was userspace based, using gpiod and spidev, which worked to gather around 500 bytes per transaction at a 1KHz rate on a Raspberry Pi3 running default Debian.
The Pi is running Raspbian Bullseye 11 with the default kernel provided by the Raspbian imaging tool, not Debian, my mistake.
And yes it is the only manually activated userspace program, there may be some other system processes running by default. But I think I may have mischaracterised the Pi as performing better than it does…
When porting the code over to the iMX it became apparent that the latency for the same code was worse than the RPi,
It’s been a bit of a piece-wise discovery process so far, as I wasn’t aware of any latency problems until I sent the code to my colleague (Connor, cc’d) who is working on the FPGA, and he did his own signal analysis.
That is where I got the ‘>1ms’ between DRDY and the SPI transaction, but having done more analysis on my end, I think the average time for the full cycle to complete can actually be a lot less, with only a few loops showing this lag.
seems the GPIO IRQ doesn’t trigger for about 1ms after the DRDY signal goes low.
I still don’t have a proper setup to accurately measure the delta between drdy falling and the spi cs going low, as I am generating the data ready pulse with the same analyser I am using to measure signals. I will try and get it set up so I can see both DRDY and SPI CS on the same monitor.
signal analysis shows a gap of about 1ms between the DRDY line going low and CS being asserted.
WIP
Is there any way to increase the priority of the GPIO interrupt?
I appreciate the methodical approach, I was a bit hasty in posting with the information I had, and agree that there are probably other causes, see black text below.
o The actual number is 432, but this will eventually increase to 864 for a complete 256 channel system. The 1KHz requirement comes from the ADC sampling rate, which should have little to no variance. Ideally there will be no dropped samples, but I have to discuss this with my colleague to see what the verilog design is currently capable of handling.
Software summary
------------------------------------------------------------
Bootloader: U-Boot
Kernel version: 5.15.129-rt67-6.4.0-devel+git.67c3153d20ff #1 SMP PREEMPT_RT Wed Sep 27 12:30:36 UTC 2023
Kernel command line: root=PARTUUID=402c09ac-02 ro rootwait console=tty1 console=ttymxc0,115200 consoleblank=0 earlycon
Distro name: NAME="TDX Wayland with XWayland RT"
Distro version: VERSION_ID=6.4.0-devel-20231012131104-build.0
Hostname: verdin-imx8mm-14947563
------------------------------------------------------------
Hardware info
------------------------------------------------------------
HW model: Toradex Verdin iMX8M Mini on Verdin Development Board
Toradex version: 0059 V1.1C
Serial number: 14947563
Processor arch: aarch64
------------------------------------------------------------
(I am running on a Yavia carrier)
There is other load on the system, the main one being transmitting the data via TCP over an ethernet connection. Currently this is deferred until there are 8 * 432 byte packets, which seems to give a fair overhead tradeoff. I have tried disabling the network transmission, but it strangely doesn’t appear to have had much effect on the worst case kernel module loop time.
In terms of improvements, I have managed to increase performance quite significantly by configuring the kernel with CONFIG_NO_HZ_FULL, and am currently experimenting with the different CPU governor options and kernel timer speeds.
I have also experimented with running the userspace application on an isolated CPU with SCHED_FIFO at priorities of 99 and 49, but this has little effect so far.
I have also noted that, given a faster DRDY signal, the average time for a transfer seems to decrease.
This is probably because of the way the kernel module currently works, which is to ignore any interrupts generated while a transfer is still in progress.
To that end, I’m wondering if there is a way to mask and then unmask the GPIO interrupt, so that it fires again immediately after a slow transaction, rather than in the worst case waiting just under 2ms for the next falling edge.
Sorry for the lack of process and proper measurements here, I hope to get some more clear measurements today, and continue to try and better characterise the system as a whole.
EDIT: I have just compiled a version of the kernel module that will raise a GPIO when the interrupt is serviced, and lower it when the spi transaction callback is received. This should hopefully give an estimate of the main time deltas, I will update here when I have some good captures.
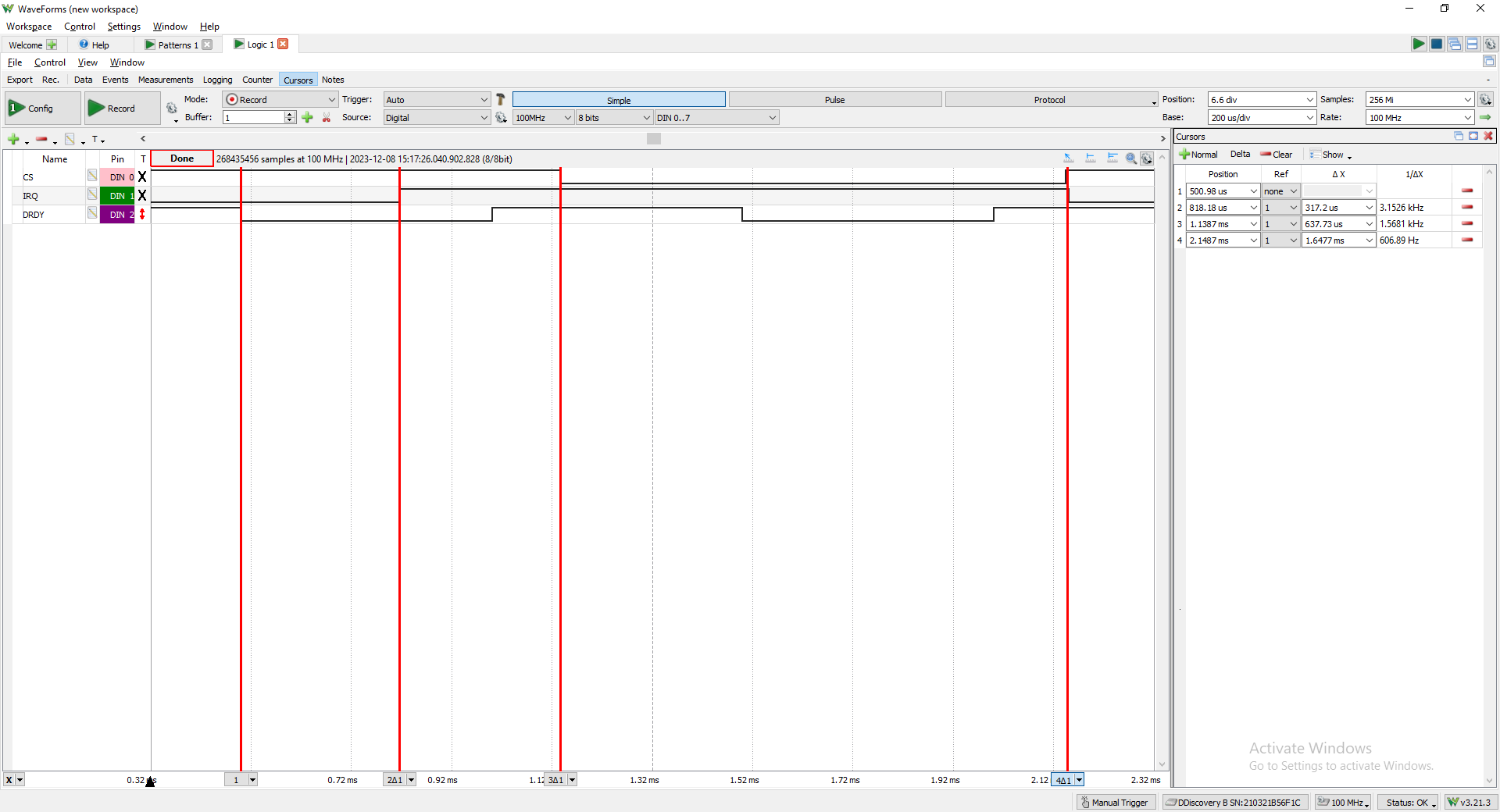
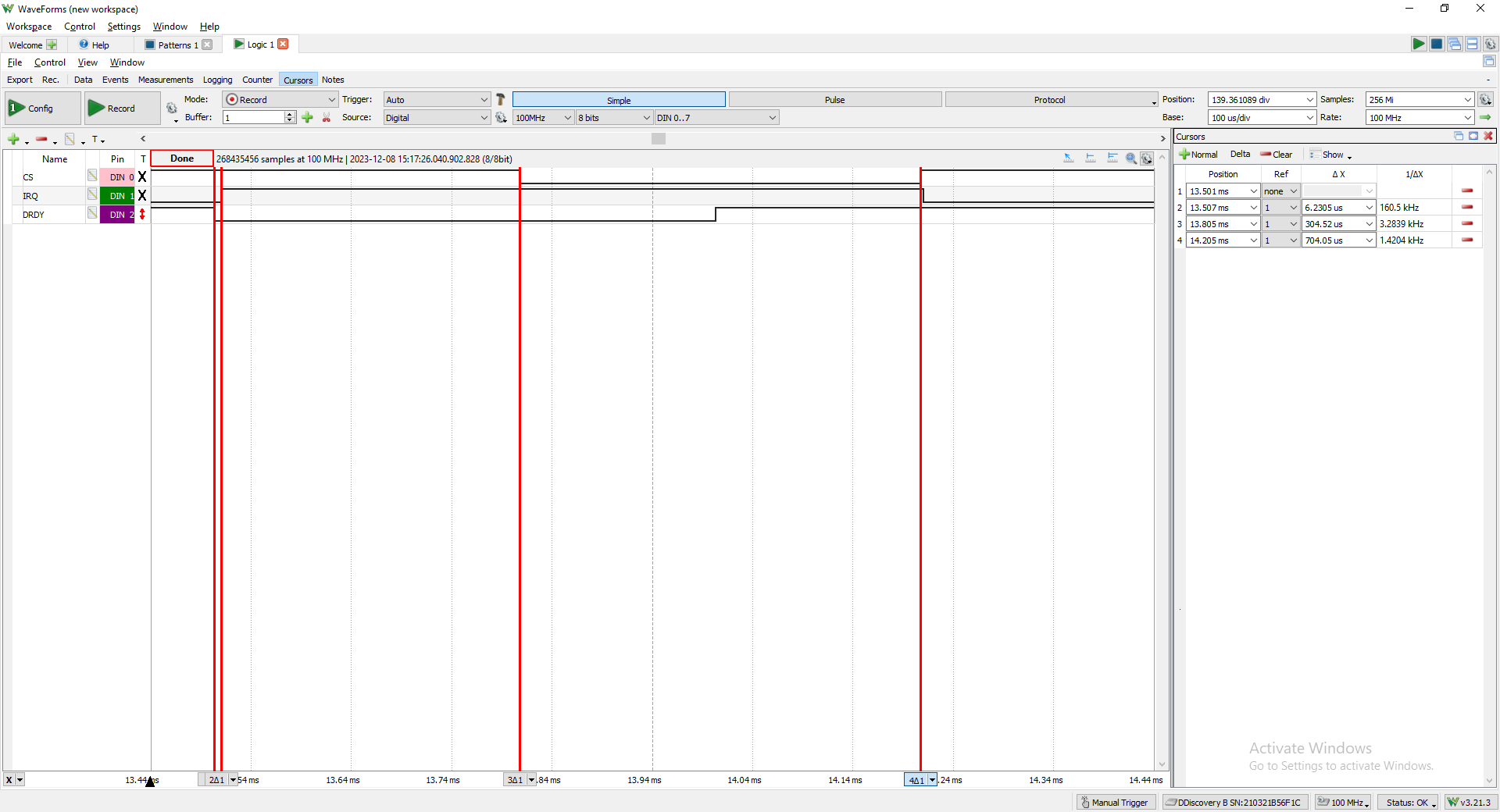
DOUBLE EDIT: I’ve managed to get some captures:
This is one of the worse cases, usually seen at the very first interrupt but occurring throughout, 300us seems to be the very worst case between DRDY going low and the soft irq handler executing.
This is one of the best cases, delta between DRDY and IRQ is 6us.
The SPI transaction time is also variable, we might be able to mitigate that a bit by increasing the clock speed, but we are already up at around 20MHz so noise/dataloss might be an issue. It would be good to know if we can ensure it that the GPIO interrupt time is consistently sub 10us, perhaps by running the module on an isolated CPU.
Thanks for your time,
Will