on a colibri imx7d emmc SOM I have partitioned the flash into 4 partitions:
mmcblk0p1: Linux kernel and root fs
mmcblk0p2: Linux kernel and root fs (backup mirror of mmcblk0p1)
mmcblk0p3: TEZI
mmcblk0p4: data
U-Boot normally boots either mmcblk0p1 or p2. The partition is the mounted read only. Partition mmcblk0p4 is mounted r-w.
Typically, this works, but very rarely the boot process gets stuck at the printout “Starting kernel”. The kernel boots even far enough to display a custom splash screen.
When I try booting the mirror partition (by giving the appropriate commands on U-Boot console) this shows the same behaviour: it gets stuck at “Starting kernel”. Power cycle will not change the behaviour.
However, when I try booting TEZI on mmcblk0p3 - again by giving the appropriate commands on U-Boot console - this always succeeds. Then I can flash the image again and the system again boots properly from all 3 partitions.
I even tried booting TEZI, mounting mmcblk0p1 r-w and replacing the zImage there (with the very same zImage file). This too fixed the error and both Linux partitions booted correctly again.
So far, I don’t know how to reproduce the error. It just happens happens very rarely without and prior indication.
How is such a behaviour possible and what could cause it? And how can I prevent this from happening again?
Could you tell us what exact 'U-Boot commands ’ are you using?
Could you also check if you are passing bootargs to the kernel? What could also help is to add earlyprintk , so that you have more information?
So the difference between booting the two Linux partitions (which gets stuck) and booting TEZI (which never got stuck) is somehow in the assembling of the boot command.
When booting the Linux partitions the kernel receives the following cmd. line parameters:
root@colibri-imx7-emmc:~# cat /proc/cmdline
rn5t618-wdt.timeout=8 ip=off root=PARTUUID=9f9d259f-02 ro rootfstype=ext4 rootwait vt.global_cursor_default=0 console=ttyS0, 19200n8 consoleblank=0
Thank you for the suggestion of earlyprintk. I will add this to the boot command and check next time the problem occurs whether that sheds any more light on what is going on - or not going on.
We just had another occurrence of the problem. Again, the boot process of the Linux partitions 1 and 2 got stuck after printing “Starting kernel.” Booting TEZI on the 3rd partition worked without problem. I tried adding earlyprintk to the kernel command line, but did not see any additional output. This time we fixed the situation by booting TEZI, mounting partition 2 (one of the stuck Linux partitions) and partition 4 (our data partition). Then we copied zImage from partition 2 to partition 4, deleted zImage on partition 2 and copied the file back from partition 4 to partition 2. Essentially, a read and write operation without actually modifying the file contents. After copying zImage back to partition 2 the problem had vanished: Linux could be booted from partition 2 and partition 1 (!) again. This is notable, since the zImage on partition 1 is a completely separate file from the zImage of partition 2.
So, there was no corruption of the U-Boot flash, no corruption of the zImage or any other file - since we could fix the problem by just a read-write operation of a file. Maybe, it could have been an arbitrary file, and not necessarily the zImage.
I suspect a problem on the emmc level or on the flash itself, because without modifying any files the problem could be fixed. However, why a problem on these levels would not affect the partition 3 (this still booted TEZI correctly) is not really clear.
we bought the modules last year. If you need the information, I can ask my colleagues to get the full serial numbers and other information that might be on a sticker on the modules.
I doubt that the problem is caused by number of resets or similar. We made a test and continually rebooted a module for many hours - and had absolutely no problems. As I said, so far its completely unclear what the issue is and what causes it.
I am guessing if the eMMC somehow got corrupted. That’s why I was wondering if this is an isolated case that happens on a single SoM or is it a behavior that you see across all the SoMs?
And to clarify again, you could also not go into recovery and re-install everything right?
And could you also maybe share with us the image.json of your custom image.
maybe it is an emmc corruption. But in this case there must be a self-repair mechanism in place, because we could get all modules un-stuck so far.
We had now the 3rd module going into this error mode within 2 weeks. These are 3 different modules. I saw the same behaviour on a 4th module several months ago. This time it happened after just switching off the power. No suspicious circumstances, just a random power cut, and afterwards the module was stuck in “Booting kernel …”
We intentionally did not go into recovery mode. We tried booting our two Linux partitions several times without any luck. Then we booted TEZI on the 3rd partition, which was successful as always. We mounted partition 1 and made a read operation on a random file:
mkdir /tmp/p1
mount /dev/mmcblk0p1 /tmp/p1
cat /tmp/p1/home/etna/.bashrc
Then we rebooted the module and suddenly, partitions 1 and 2 were un-stuck and booted their respective Linux system again. So, mounting one of the problematic partitions and executing a file read operation was already enough to resolve the problem. Not even a write operation is required. I’m quite sure previously it was already the read operation on the zImage that helped; the writing back of zImage was not even necessary.
The question is still though: what is different in the read operation on file system level than reading the files (ftd and zImage) by U-Boot with mmc_load? And why is partition 3 seemingly unaffected? Or is it the mount operation that already fixes the problem?
I attach serial number information of two of the problematic SOMs, as well as the image.json file we are using to define the 4 partitions.
Thank you for the detailed answer. The problem you are facing, however, seems a little strange to us as well. So we have the following recommendation, in order to get us closer to the source of the issue.
Could I ask you to take some md5sums of the zImage files whenever the problem happens again. You could even perform the following procedure when the problem happens:
boot tezi
mount partition 2 again
md5sum their zImage
copy it to partition 4
md5sum the file at the destination
copy it back and do md5sum again
You could also do that right after the first md5sum just compare it to their original zImage. I would expect that if you are not able to boot, the read md5sum of the zImage on your boot partition doesn’t match the md5sum of their original zImage.
If it does, the problem is not the file, and we would have to try a different debug methods.
please find attached the U-Boot environment as it prints out on the console. The image.json is already attached to my last post (last line below the second picture).
I will try your idea with the md5sum. However, since we do not know how to force the problem we have to wait until another module by chance goes into this state. So this may take a while.
Actually, I don’t expect the checksum to mismatch. In our most recent attempt we were able to fix the problem by just reading a random file. So, even if the original zImage would be corrupted an error correction would kick-in and repair already on reading the file. Reading the file for calculation of md5sum would thus already correct and fix the problem. Moreover, in our last attempt we did not touch zImage, but made a read operation on a totally different file. Still, afterwards the module booted again. How could that have corrected a corrupted zImage?
sorry there was some boot print-out at the start of the file. I cut it away and here is the print-out from U-Boots printenv.
If this still does not work I will send the file to your e-mail address.
Thank you for all the information here.
As this is not a common issue, I have escalated this internally for further examination.
We will let you know once we have more information.
Hello @Otmar,
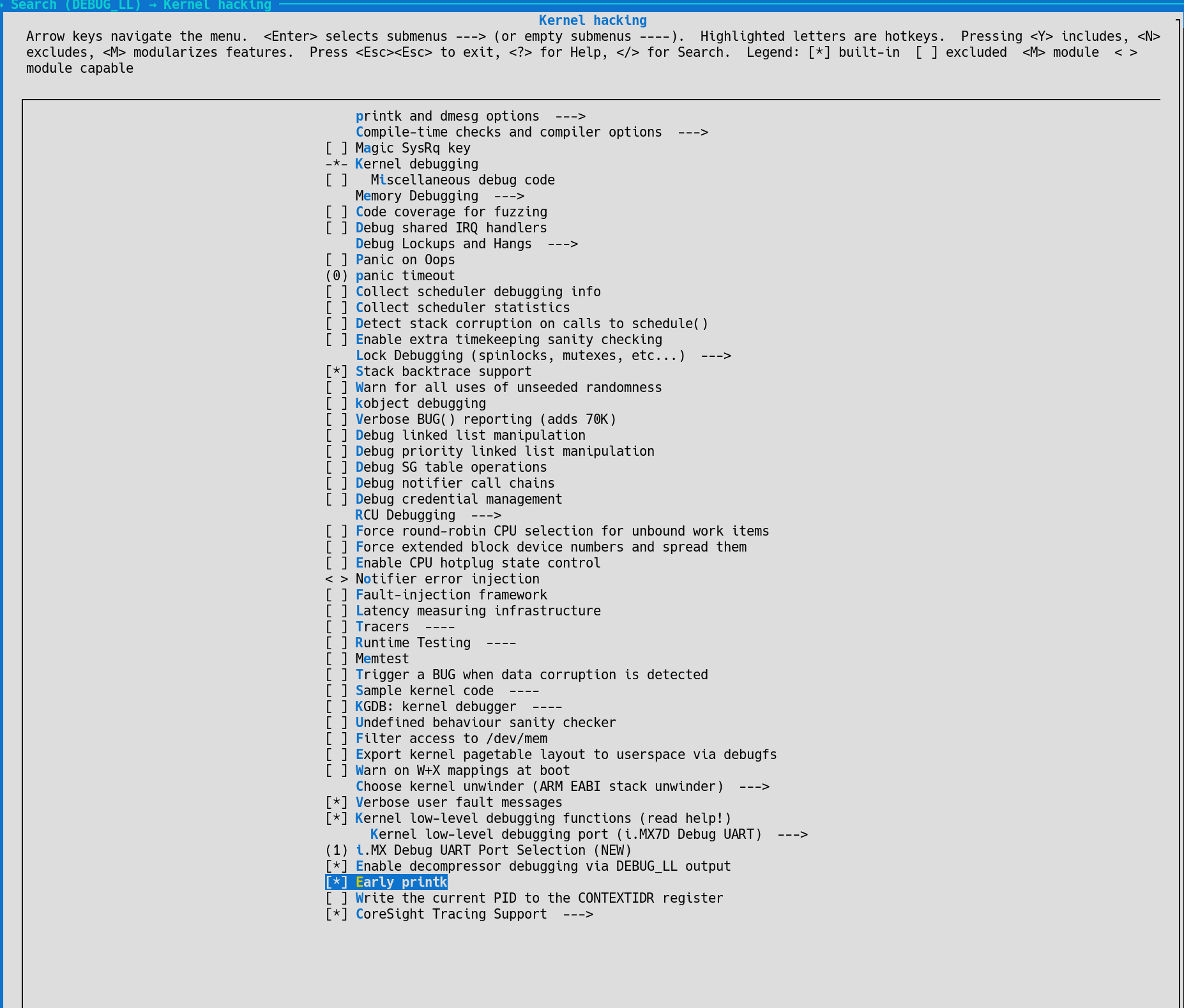
maybe it would be good to have early printk enabled the next time this issue happens. Unfortunately, to enable this feature we need to recompile the kernel. Would it be feasible to recompile the kernel with this feature enabled and put it on some devices?
These are the settings that need to be applied:
It should not be necessary to leave the earlyprintk flag activated on the modules, but the kernel with earlyprintk compiled in should be there. The flag can be enabled after the problem manifested itself, and hopefully we would see some kind of output coming from the board.
I suggested that we do this md5 test, but reading back on your description I agree with you. It seems that for whatever reason just mounting the partition and reading something from it already makes the problem go away, so by doing that we would probably throw away an opportunity to try to extract more information when the problem is “active”.
Please let me know if it would be possible to put the recompiled kernel in some devices…
ah, earlyprintk must be enabled in the kernel config first. That explains why my attempt to use it failed to generate any more output. Yes, we can activate this feature. But most likely we cannot get the new version onto the modules we have in the field. We intend to set up a batch of modules in our lab for intense testing, hoping to re-create the issue. We can load the modified kernel to these modules. It will be a comparatively small sample size, but maybe we are lucky and one of the modules hits the problem.
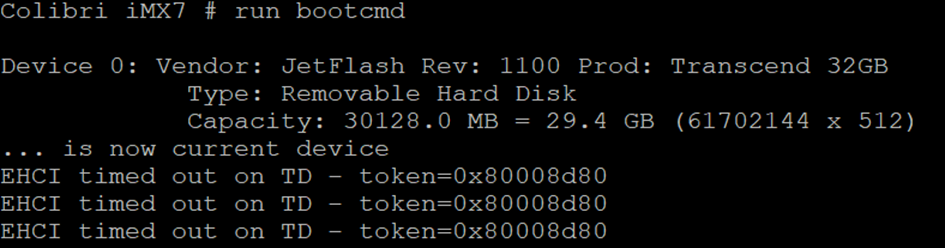
as per the instructions, because of the kernel version we are using (4.14), I’m trying the Automatic Fix Image or via the Recovery Mode. None of the methods worked for me.
In the Recovery Mode case I get the following error:
Yes that’s right. To be able to fix the module you would have to install some image with kernel > 5.4. An easy and fast way would be to grab the Toradex Reference Minimal Image with the corresponding kernel. Its very fast in installing. You can either find it directly in the Toradex Easy Installer or you can download it here. For kernel 5.4 that would be BSP 5.7.
At this point, I would like to ask how many units you have with this behaviour?