Hello everybody,
I’m staring using the Colibri iMX7D and i want to know what is the best approach to send data blocks from the M4 to the A7.
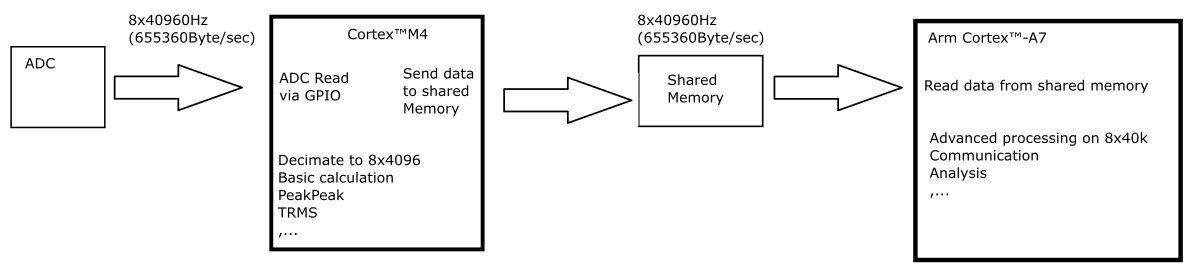
The target process is the following :
-
Cortex M4 manages ADC conversion via GPIO (8x Channel at 40KHz)
-
Cortex M4 transfer the data to the A7 via shared memory or another way…
3a) Arm Cortex A7 read the data and do some processing on it
3b) Cortex M4 decimate by 10 the data to keep 4kSample per second and do some processing on it
How can i transfer this amount of data from the M4 to the A7 ?
I have played a bit with RPMSG but i have the feeling that it more for exchanging small message (256byte) between both processors.
Another question is how extend M4 data memory ? I need to do processing on 8x4096 float values. What is the best memory for that and how interact with this memory ?
Thanks for your support
Dear @joel_mcm
Data Exchange Mechanism
To access shared memory you will need a driver on the Linux side. Rpmsg is already there, so this is the most straight-forward choice. However, you could write your own simple driver which does nothing but accessing a shared memory area.
The RPMSG buffer size can be modified in the Linux rpmsg driver:
arm/mach-imx/imx_rpmsg.c. Look for the constant RPMSG_BUF_SIZE.
Afaik the default buffer size is 512 bytes (not 256).
Available DRAM for the M4
There is 2MB of DRAM reserved to be used by the M4:
-
0x8FE_00000 - 0x8FFF_FFFF
A small share of this is reserved for the rpmsg library (initialized from the Linux side), and therefore cannot be used for other purposes:
-
0x8FFF_0000 - 0x8FFF_0FFF and
0x8FFF_8000 - 0x8FFF_8FFF
Additional Considerations
Note that the memory selection does hugely influence your application performance. Accessing the tightly coupled memory (TCM) from the M4 can be done in 1-2 CPU cycles. Accessing the OCRAM takes roughly 10-20 cycles, and the DRAM is even slower.
With this background, my approach would basically be:
- place all the code in the TCM
- place as much of the variables you use also into the TCM - especially variables which you access more than once.
- sample the ADC data in a loop and apply the decimation filter after each sample (maybe this is a way to reduce the size of the mentioned 8x4096 floating point buffer?)
- Transfer the decimated data to the A7 core (which means copying the data to the DRAM), using rpmsg or a customized protocol for shared memory.
Regards, Andy
Dear Andy,
Thanks for answering.
I will try first to set a bigger RPMSG message size.
I found this information on the website :
I will try that.
In a second phase, i will do my own driver, because in don’t need the buffer in the both directions like the RPMSG driver.
Afaik the default buffer size is 512 bytes (not 256).
Yes, but this is 256 in each direction? no ? It’s possible to use both ring to the same direction `?
Dear @joel_mcm
The two rings are just linked lists, one for each direction. This cannot be changed.
Each ring element is only 16 bytes in size and does not contain the actual data, but only a pointer to a buffer. Therefore you can use the full buffer size (512 Bytes) to transfer data in one direction.
If you use rpmsg to only transfer data from M4 to A7, all buffers will be used for this direction, so there’s only a small overhead for the ring elements. In your case you can probably reduce the number of ring elements, as you are working with a few large buffers.
Regards, Andy
Dear @andy.tx ,
Therefore you can use the full buffer
size (512 Bytes) to transfer data in
one direction.
Thanks for your answer, then the RPMSG can be a good solution.
I will open another topic especially about increase RMPSG buffer to share the detail of how increase it.
(I have try to increase it based on the “Change RPmsg Buffer Count and Size” chapter but it’s not working for the moment. I should miss somethings