Hi Lloyd,
I can identify what’s happening here. I’m imagining that the devices that failed were provisioned, used for a while, and then re-provisioned as new devices at some point, right? First, a short explanation of the security feature that is causing this.
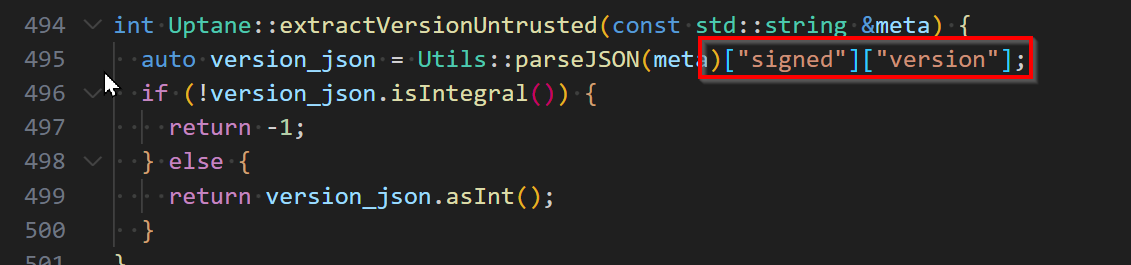
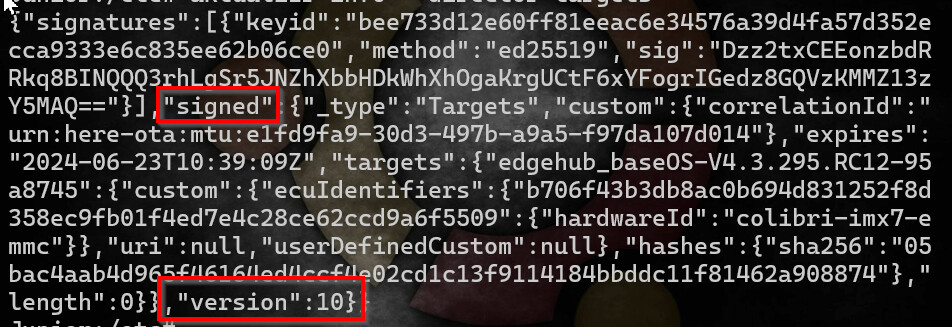
Rollback protection is a really important property for a software update system to have. You don’t want someone to be able to replay a message from the software repository saying “Install my_app_v.1.0.0-buggy” to cause devices to install some previously-valid version of software. Torizon Cloud protects you against that in several ways using the Uptane security framework. One of the things it does, is perform a check to ensure that the version number of the director targets metadata (which is essentially the install instruction) always monotonically increases. Because each device can be independently directed to install its own software, that version number is unique per device. When you start an update, our backend generates and signs new metadata (including an incremented version number) that the device will validate. So far, so good.
Uptane also has this concept of primary and secondary components–or subsystems, as we call them in Torizon. Each subsystem independently validates the update metadata, so even if you have a subsystem that’s an external microcontroller connected to the main device over a link layer you don’t trust, you’re still protected from rollbacks and all the other threats that we consider in the software update system threat model. Unfortunately, what seems to have happened here is that the devices that are currently failing have subsystems with incorrect versions of director targets metadata–almost certainly because they were re-provisioned at some point in the past without the subsystem’s metadata being reset. I’m not 100% sure how that would have happened, but I think that older versions of aktualizr may not have dealt with the situation properly if aktualizr wasn’t shut down cleanly and the device was re-provisioned into the same repository. Today, when you re-provision a device, we make sure to reset the metadata of all subsystems as part of the provisioning process, just in case aktualizr doesn’t do it properly.
So, for example, this is what probably happened:
- You provision device
foo
- It stays connected to Torizon Cloud for quite some time, gets updates, etc. Every time any subsystem of the device is updated, or the metadata expires, the director targets metadata version number gets bumped, until it reaches version N.
- At some point, you re-provision it as device
bar. As far as the backend is concerned, this is a new device, so its targets metadata version starts back at 1. However, there was an issue with the re-provisioning process for one of the subsystems. Nothing seems to be wrong: the subsystems are all registered and reporting correct information, and updates to the base OS and any subsystems that were new (or that hadn’t been updated when the device was named foo) will work just fine.
- You send an update to the subsystem that still has the version N director targets metadata from when it was named
foo. The metadata is still signed by the correct roots of trust for your repository, so it passes the initial checks. But since you’re sending it update instructions via director targets metadata with version number M which is less than N, the subsystem rejects it, thinking that it’s an attacker trying to fool it by replaying metadata from the past.
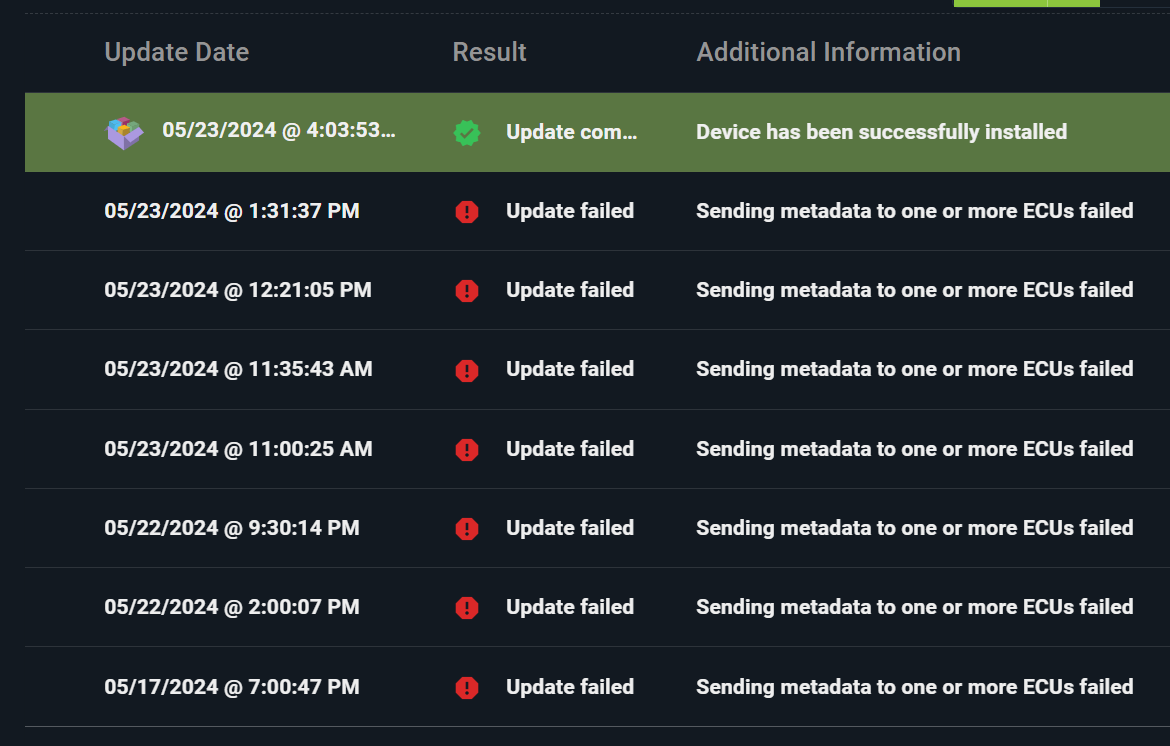
So, in summary: the issue is that Torizon Cloud and aktualizr both agree that the device’s director targets metadata should be at version M. The docker-compose subsystem you’re trying to update, though, has already seen version N, which is higher than M (from when it was provisioned previously), and thus flags the update as a rollback attempt.
There are essentially two ways to fix this. One way is to stop aktualizr on the failing devices, delete the file /var/sota/storage/<subsystem-name>/sql.db, then restart aktualizr. You’ve already said that’s not a desirable solution, though. The other is to sufficiently increase the director targets metadata version for the failing devices, until it’s greater than whatever version the failing subsystem has left over in its storage. One way to do that is simply to send a bunch of updates; the director metadata version will increment by one every time the device picks up a new update, and eventually the version number will reach the number that the problematic subsystem has in its internal storage. I understand that might be equally undesirable, though. We’re looking into another possible solution on the back-end, but will need a couple of days to get back to you on that.