Hi there,
I’m having difficulty progressing with a problem in upgrading the base os of our fleet. As it stands, there are approximately 50 units which continuously and stubbornly return “not_affected_running_assignment” after a PostUpdate request. To start with, here are the details for just one of the devices.
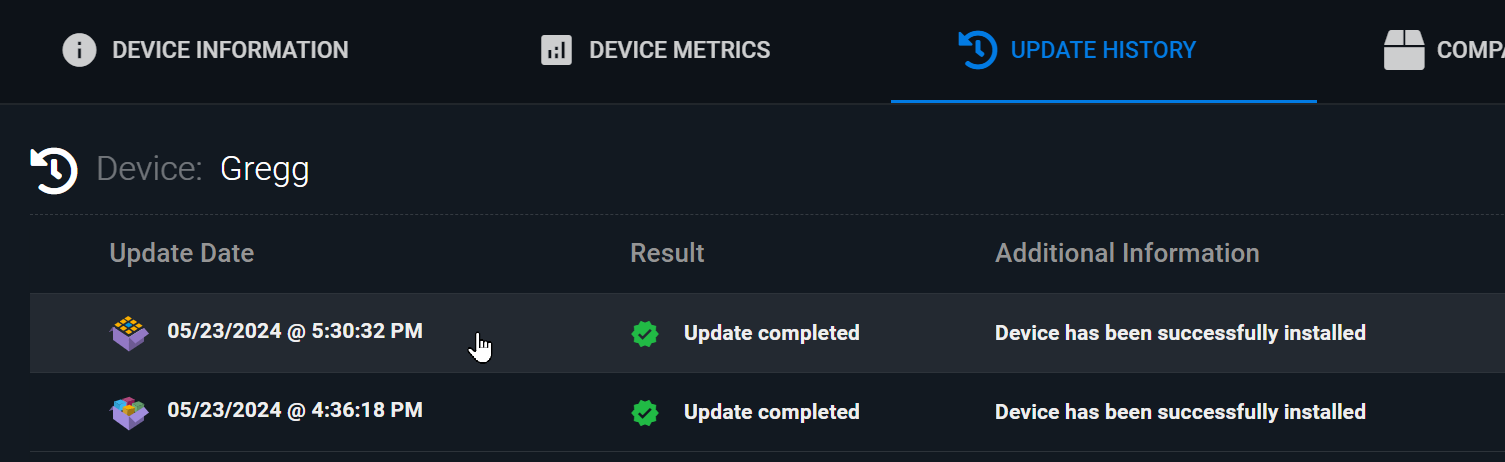
Using app.torizon.io, the upgrade is logged as successful on 23/05/2024:
However, the update status is listed as “in progress”:
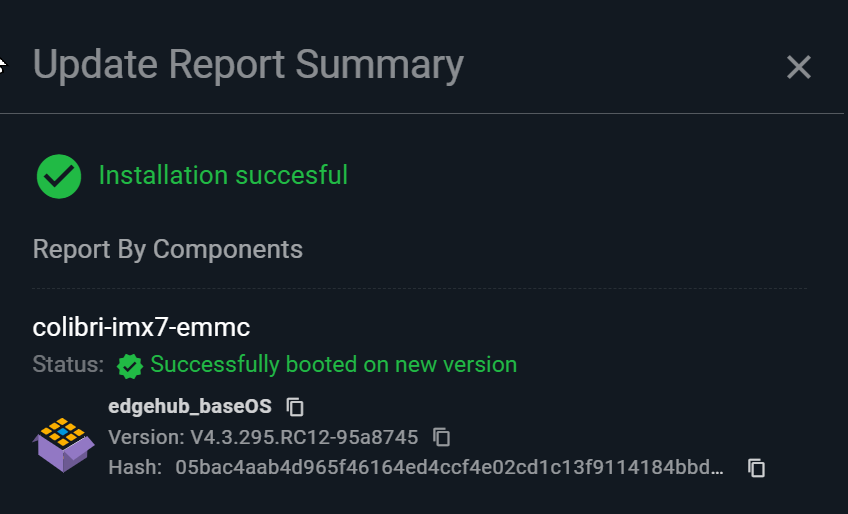
Upon clicking on “More info”, the update for our version 4.3.x.x is listed as successful (not in progress):
But under “Device Components”, the installed package remains at our old 4.2.x.x:
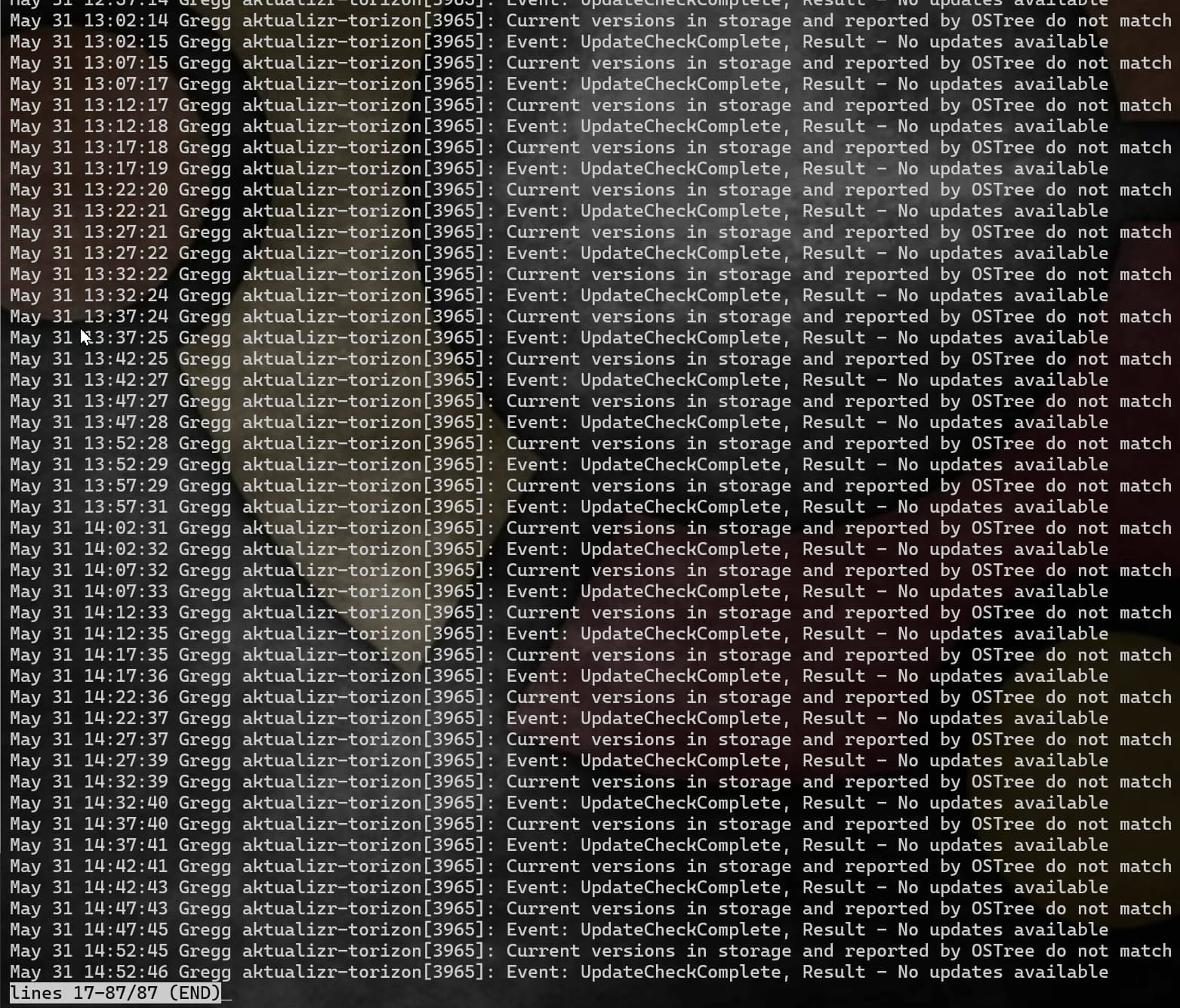
If we log on, this is what we see for the aktualizr logs:
And here is the output of ostree admin status:
After seeing (pending), I executed a reboot, but it booted on the same (old) version.
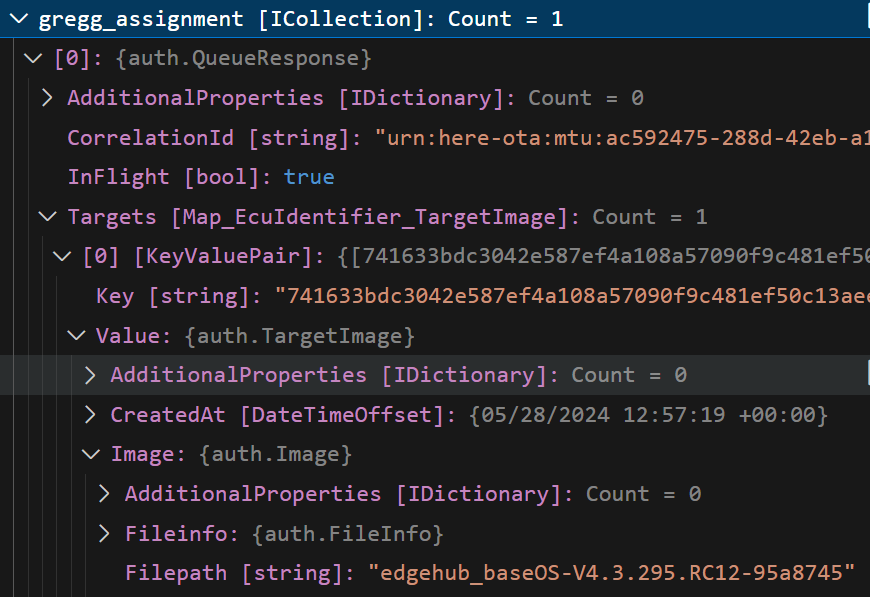
Finally, using the api, I see an InFlight: true uptane assignment for the 28/05/2024 with the correct (newer) version number:
Can this be solved without reprovisioning or modifying files please?
Looking forward to your response,
Lloyd
Hi, I’m the Toradex AI Assistant. I’m in early beta, and I would appreciate your feedback.
The Toradex Support team will follow up with you shortly!
Did you like my answer?


Hello Lloyd,
It seems like the device is experiencing an issue with the update process where the new version is recognized but not properly applied, resulting in the device booting into the old version despite the update being marked as successful. This can happen due to several reasons, including issues with the update process itself or the device’s state preventing the switch to the new version.
Here are a few steps you can take to troubleshoot and potentially resolve the issue without reprovisioning or manually modifying files:
-
Verify Update Commit: Ensure that the commit hash for the new version matches between the server (as reported by app.torizon.io) and the device (ostree admin status). Discrepancies here could indicate an issue with the update delivery or application.
-
Check for Update Locks: Sometimes, updates may not apply due to locks or other processes preventing the update. Although you’ve mentioned not wanting to modify files, checking for the presence of such locks can be done via logs and does not necessarily involve changing system files.
-
Review Aktualizr Logs: Since you have access to the aktualizr logs, look for any errors or warnings that could indicate why the update is not being applied. This might provide clues on whether the update process is encountering specific issues during the application phase.
-
Force a Manual Check for Updates: Sometimes, triggering a manual update check can help resolve issues where updates are not being applied as expected. This can often be done through the device’s management interface or via command line, depending on your setup.
-
Examine Bootloader Configuration: Ensure that the bootloader configuration is correctly pointing to the new version. In some cases, the bootloader may not update its configuration to boot into the new version, causing the device to revert to the old version after a reboot.
-
OSTree Admin Cleanup: Running ostree admin cleanup can help remove any residual or temporary files from incomplete updates, which might be causing conflicts. This is a safe operation that cleans up unused objects in the OSTree repository.
-
OSTree Admin Undeploy: If a specific deployment is causing issues, you might consider using ostree admin undeploy <deployment-index> to remove the problematic deployment. Be cautious with this command, as it will remove the specified deployment, which could affect the device’s ability to boot if not done correctly.
If these steps do not resolve the issue, it might be necessary to delve deeper into the system’s update mechanism and logs to identify the root
Please, also check if these links can help you solve your problem:
Device Tree Overlays on Torizon | Toradex Developer Center.
Greetings @lblackbeard,
This seems strange. So first of all the log line Current versions in storage and reported by OSTree do not match, does not inherently mean there is an issue. It just means the OSTree version stored in the sql.db Aktualizr uses, does not match the OSTree version that ostree itself is reporting. This can happen for various non-error related reasons.
The more confusing part is all the conflicting information you are seeing. Some parts of the Web UI say the update is succesful, other parts are saying it’s sitll in progress. Then, on the actual device it’s still on the previous version and as you said won’t boot into the updated version.
Let’s try and dissect what’s happening on the device-side first.
After seeing (pending), I executed a reboot, but it booted on the same (old) version.
The “pending” flag you see should mean that OSTree will boot into this version unless something prevents it to do so. The question is what is doing this? Do you see any boot logs or anything that would suggest the system rolled-back to the old version?
Is the rollback environment variable in U-Boot set maybe?
Also have you ever re-provisioned this device in the past?
Best Regards,
Jeremias
Thanks @jeremias.tx ,
I see that the rollback flag was indeed set and after setting it to 0 and rebooting, the system has booted onto the correct version.
How is this flag usually cleared or can it only be cleared manually? Is it possible that aktualizr reported “no updates available” because the upgrade was already downloaded (but just stuck in the “pending” state)?
The conflicting information is indeed troubling, is it to be expected for devices that have rollback=1?
Cheers,
Lloyd
I see that the rollback flag was indeed set and after setting it to 0 and rebooting, the system has booted onto the correct version.
That explains the observation on the device-side.
How is this flag usually cleared or can it only be cleared manually?
The flag should be cleared only by Aktualizr upon a successful update. I learned that in the past your team at Senceive used scripts to manipulate the value of the rollback variable outside of the control of our usual update system. Perhaps that is the case on these devices? That could explain the strange behavior on the device as these variables should only be manipulated by our update system. Manipulating them outside of the control of our update system could cause strange behavior.
Otherwise we need an explanation for what on your system set the rollback variable in the first place.
The conflicting information is indeed troubling, is it to be expected for devices that have rollback=1?
Our team is looking into the conflicting information on the Web UI. Our engineers require access to your repo to investigate further. Could you give access to your repository to this email: temitope.adeyeri@toradex.com
Here’s our documentation on repository sharing if you don’t know: Repository Sharing | Toradex Developer Center
Best Regards,
Jeremias
The flag should be cleared only by Aktualizr upon a successful update.
Fair enough. And what happens if an update fails, the system boots on rollback and an attempt is made to upgrade to the same version that just failed? Will it say “No updates available”? It’s important that we have a way of reattempting upgrades as via greenboot we’ve defined success as something that isn’t deterministic (successful cellular connections depend on stochastic environmental conditions).
I learned that in the past your team at Senceive used scripts to manipulate the value of the rollback variable outside of the control of our usual update system.
Yes, unfortunately the contractor responsible for porting our system from Yocto to Torizon directly manipulated the rollback variable and we have only just picked this up. We have rewritten the script and will be moving from bench/dev to testing on our in-house fleet this week.
Could you give access to your repository to this email: temitope.adeyeri@toradex.com
Read access granted. I see we signed a mutual NDA in 2020 so it shouldn’t be a problem if that needs to be full access - just let me know.
And what happens if an update fails, the system boots on rollback and an attempt is made to upgrade to the same version that just failed? Will it say “No updates available”?
You should be able to re-attempt the same update. Aktualizr will only claim “No updates available” if the currently installed OS is the same as the OS you’re requesting an update for. Assuming the previous update attempt failed, then Aktualizr would not consider that attempt as “installed”.
Read access granted.
Thank you, I’ll let our developer know so he can go and take a look.
Best Regards,
Jeremias
Why would you think then that it was claiming no updates available while the api said an upgrade was in progress and the os was rolled back?
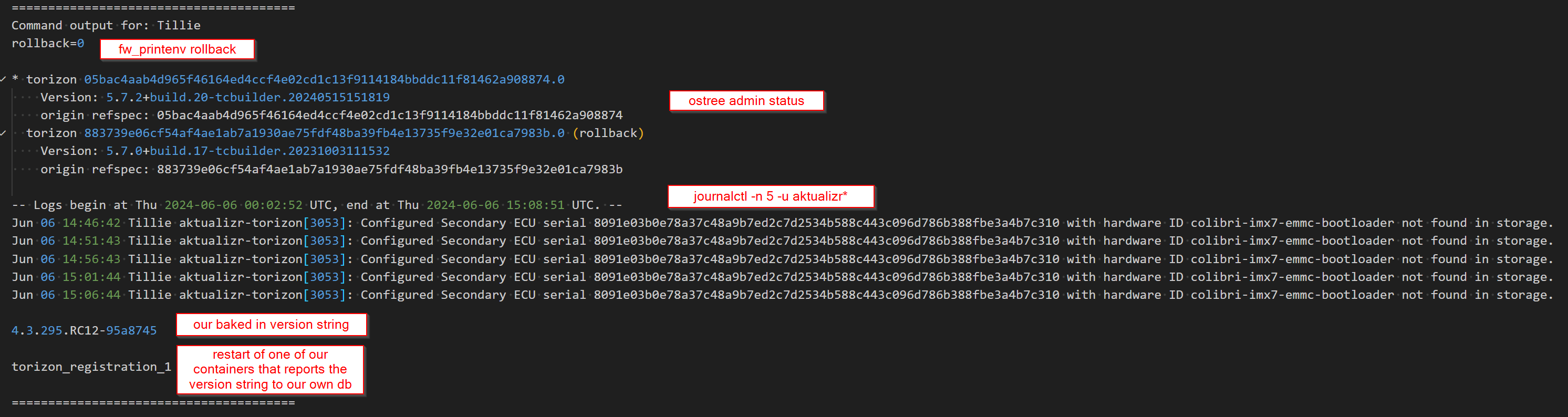
I have another related problem, apologies. I’ve been tackling the rollback problem by programmatically executing fw_setenv rollback 0. Although this works to get the system running on the intended OS, which I can verify because we bake in a file with the version string, aktualizr seems not to work anymore in that the last seen stamp is not being bumped, the api says an update is still pending, the api says the “old” (rolled back) version is running (when the string we baked in shows it’s the new version and so does ostree admin status) and the aktualizr logs show an issue with the bootloader ecu (we’ve moved from 5.7.0 to 5.7.2).
Below is a snip of the output, which is almost identical for the ~90 units where fw_setenv rollback 0 was executed.
I know you mentioned that the storage location for aktualizr data is unaffected by ostree, so what else could it be that so consistently causes problems with the bootloader subsystem when the rollback is applied and then undone? Or is the BL thing a red herring?
Why would you think then that it was claiming no updates available while the api said an upgrade was in progress and the os was rolled back?
I’m just theorizing, but the server could have gotten strange conflicting information from the device. It may be a side effect of the rollback variable being set outside of the normal process of the update. Though this issue also may be related to the other issue you mentioned just now, speaking of which.
I have another related problem, apologies. I’ve been tackling the rollback problem by programmatically executing fw_setenv rollback 0. Although this works to get the system running on the intended OS, which I can verify because we bake in a file with the version string, aktualizr seems not to work anymore in that the last seen stamp is not being bumped, the api says an update is still pending, the api says the “old” (rolled back) version is running (when the string we baked in shows it’s the new version and so does ostree admin status) and the aktualizr logs show an issue with the bootloader ecu (we’ve moved from 5.7.0 to 5.7.2).
This issue and those log messages you just shared. Have you ever in the history of this device, moved from 5.7.0 to 5.7.2 then back down to 5.7.0 and now to 5.7.2 again? Your logs look suspiciously like this has happened.
The issue is that in 5.7.2 we added the bootloader component, as an update target. So when you go from 5.7.0 to 5.72 this component gets added and registered. But, if you go back from 5.7.2 to 5.7.0 this component gets “unregistered”, which is fine. But, now if you try to go back to 5.7.2 a second time the system will try to register this bootloader component again, but this “re-registering” of a component is an illegal action in our update framework due to security reasons.
This all leaves your device in a state where it can’t communicate properly to the server anymore, which sounds like what is happening to your devices right now. This interaction is documented and described here: Bootloader Updates in Torizon OS | Toradex Developer Center
You can see there is a documented workaround for this by removing rm -rf /var/sota/storage/bootloader.
In the future please be careful when updating/downgrading your devices, in addition to the manual setting of rollback.
Best Regards,
Jeremias
Thanks Jeremias,
It looks like the 5.7.0 —upgrade—> 5.7.2 ----rollback—> 5.7.0 —manual “unrollback”—> 5.7.2 with the BL considerations was indeed the problem. It’s sorted now after executing rm -rf /var/sota/storage/bootloader.
I would certainly have preferred not to run fw_setenv rollback 0 but the “updates not available” meant I could not use the api to recover these systems. As for fw_setenv rollback 1, would the behaviour have been different if the rollback were instantiated via the intended path? - the link seems to indicate that ota functionality is compromised when moving back before 5.7.2 no matter the instigator.
Regardless, we have a system running now to programmatically take care of the issues discussed in this post and for now it seems that’s working.
Thanks for all your help.
Cheers,
Lloyd
would the behaviour have been different if the rollback were instantiated via the intended path?
It would most likely not. The issue is with updating to 5.7.2 twice. Going to 5.7.2 once is fine, as well as going back to 5.7.0 or earlier. But, once you go back from 5.7.2 you should not attempt to go to 5.7.2 again.
For future reference, if you make use of our subsystem updates to add an additional update component to your system: Subsystem Updates Overview | Toradex Developer Center
Same concept applies. Basically don’t try to do an update path that adds, removes, then adds again the same update component.
All that said, glad to see you were able to get things cleared up now on your devices.
Best Regards,
Jeremias