Linux BSP 2.8.7
Colibri T20 with Viola carrier board
We only just noticed that the Yocto linux version is reporting 1020MB of flash when it is only supposed to have 512MB. I used “lsblk” to get that result. But I stumbled across this because I was transferring a large file 1.2GB to fill up the flash to test what happens when the system runs out of space. As it went past 450MB and then 520MB I was really surprised. When it stopped around 800MB and the file system turned to read-only then surely the space is greater than 512MB.
Is this normal?
Is yocto doing weird things?
Could this potentially cause issues of writing over flash areas it’s not supposed too?
The Colibri T20 always ships with Windows CE so we use the method from Toradex website to get Uboot and version 2.8.7 of Yocto installed.
We have had a couple of issues with the Colibri T20 like flash corruption, so we are just wondering is this the cause?
Some Colibri T20 modules have 1GB of raw NAND memory on board, a significant part of which is mounted as RootFS. Could you please provide the full name and hardware revision of your Colibri T20 module? For example, ‘Colibri T20 512MB v1.2’.
They are all Colibri T20 512MB v1.2A modules
So they could be 1GB, that makes more sense, I thought I might have been programming them incorrectly.
We have had at least 4 T20 modules now have a corrupted flash and fail to boot. I was hoping it was related to this weird extra flash but obviously not, we have also used Colibri T30 modules and never had a single one have corrupted flash. Can you think of any reason for the difference?
The Colibri T20 512MB v1.2A modules have 1GB SLC NAND flash on board. Could you please provide more details about the flash corruption? Have you tried to re-flash the modules that fail to boot? Can you explain when and how the aforementioned corruption occurred? What kind of application are you running on the modules? Please note that all flash-based devices have limited erase block resources, so frequent writing can lead to flash degradation and corruption.
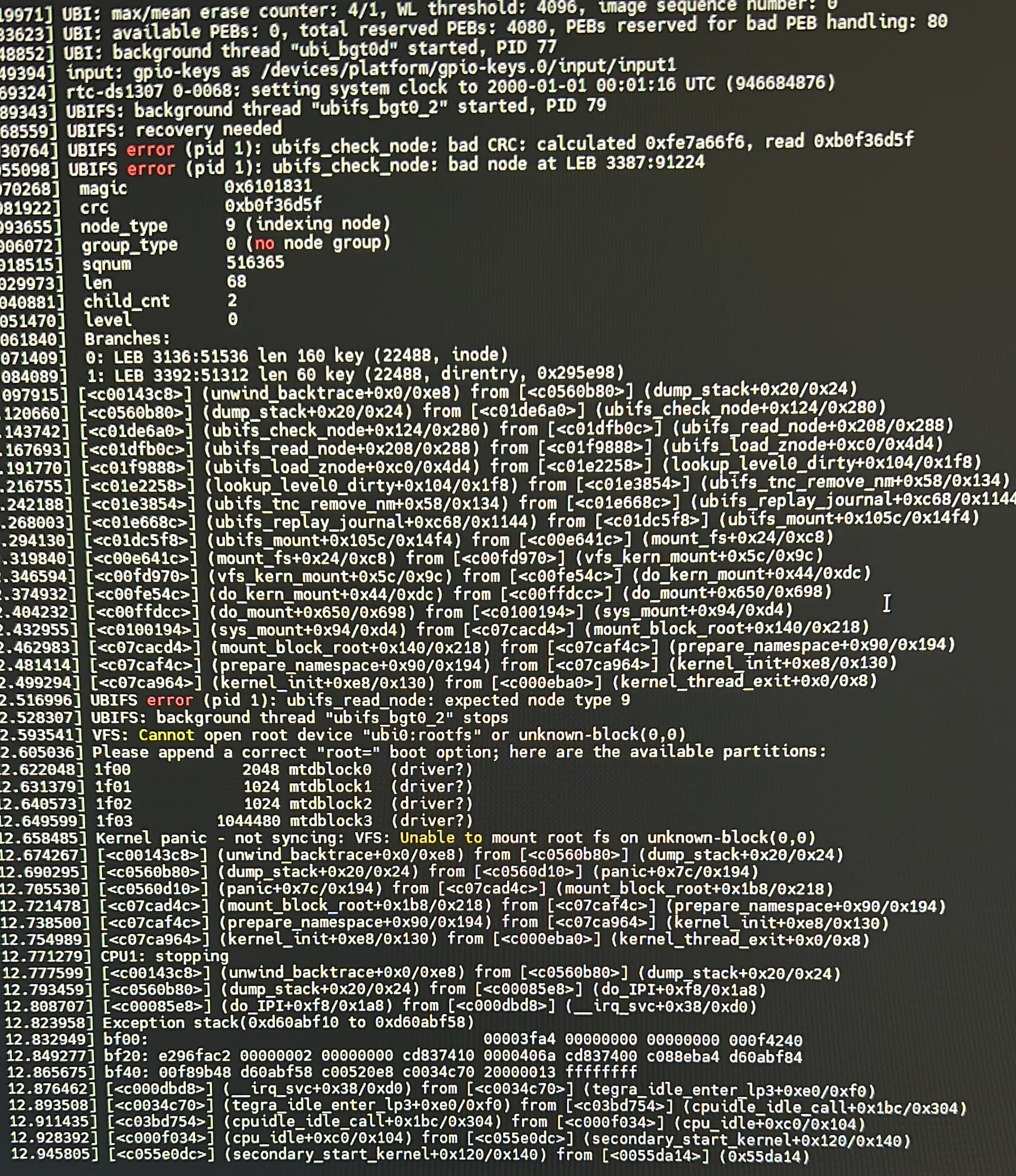
We have had 3 devices so far have this flash corruption and 5 devices in the field stop working and we suspect have the same issue. I took a screenshot from the debug serial port:
If we erase the flash and start from scratch then it’s fine and we get it working again but that is not possible for systems in the field that are embedded in boxes etc.
Is there a way to recover the system from this point?
Our system has no screens or attached devices other than using a serial port to communicate with a satellite unit. I wrote two daemons in C++, installed in the OS that write to an SQL file and also read/write files to the root directory to send/receive files back to customers connected via Bluetooth. The system can be turned off at any point and we currently have no battery backup or capacitors to hold power. We are fairly certain the system is booting and running when power is turned off, but obviously this can happen at any stage.
I tried to reproduce the error by turning off the system while writing/reading from the flash and it hasn’t failed yet. I know the UBIFS is designed to handle these issues but obviously something is going wrong if we have had 3 confirmed flash issues and maybe 5 more.
I can see 2 reasons for file system corruption in your case
Ungraceful shutdown (power cut)
Flash cells wearing.
Although UBIFS is designed to be transaction safe and should recover after an unexpected power cut, there isn’t a 100% guarantee. For instance, consider this thread. Frequent writing to flash can result in the appearance of new bad blocks due to flash wear. Can you assess or determine how many write operations per minute your SQL DB and BT software create? I would suggest moving the files you use for BT communication to a RAM disk. If your SQL database is not large, it can also be moved to a RAM disk, after which you can periodically create snapshots on your internal flash. You could also consider moving the SQL DB location to an SD card or USB flash drive.
When one really needs to wipe whole nand including UBI headers, UBI partition should be ubiformat’ed with -e switch, specifying old mean erase counter. You can’t do it from mounted UBI volume, instead you need to boot from NFS/SD/etc, ubiformat -e, then reapply UBI rootfs, kernel and dtb.
Since kernel used in 2.8.7, I believe UBI code was patched several times improving reliability. Still you may have issues cutting power unpredictably. For sudden power cut read only rootfs should be used. overlayfs can be further used to store RW changes in RAM, which further may be copied periodically (and not to often for premature wear, perhaps only writing when there’s a real change in you data) to two additional UBI volumes, copying data each time to volume with oldest data. On power on determine last written volume with healthy data, restore to tmpfs, mount flash overlay.
Typical SLC NAND flash endurance is approximately 100K erase cycles per block. To track flash wear, you can monitor the growth of bad block count over time. To find the MTD device associated with your UBIFS partition, use the command cat /proc/mtd . For Colibri iMX6ULL, the output will resemble the following:
I looked this up on google but didn’t really understand what the counter represents. What does this actually mean?
Since kernel used in 2.8.7, I believe UBI code was patched several times improving reliability. Still you may have issues cutting power unpredictably. For sudden power cut read only rootfs should be used. overlayfs can be further used to store RW changes in RAM, which further may be copied periodically (and not to often for premature wear, perhaps only writing when there’s a real change in you data) to two additional UBI volumes, copying data each time to volume with oldest data. On power on determine last written volume with healthy data, restore to tmpfs, mount flash overlay.
Is there any examples on how to acheive this? I found a Toradex webpage on how to create a read-only rootfs but nothing about partitioning a flash or creating UBI volumes and how to swap them on power up.
I will keep looking as well and report back if I find my answers.
UBI man/mean counter(s) represent worst PEB erase counter and average PEB erase counter. Sometimes these counters seem falling down a bit, which is surprising, but still they seem being quite consistent are useful to feel real wear level. /sys/class/mtd/mtd4/bad_blocks for some reason always stays zero, perhaps it will start rising when NAND will be about to die, I don’t know. In contrast bad blocks reported by UBI (ubinfo -a) seem matching what MTD reports at kernel boot time. The most weared Colibri I have at hand has max/mean of 80000/5000. Though the most wearied block is 80% of max erase claimed in NAND chip datasheet, /sys/class/mtd/mtd4/bad_blocks still reports zero.
Example of how to upgrade to more fresh kernel with UBI code improved? Perhaps just take last main line kernel and see what broke since your old kernel and what useful features got dropped. Hooray if none, just upgrade.
If you were asking about read only rootfs, then google a bit and you will see there’s no single and the best recipe for it. Starting point is in Yocto docs: 30 Creating a Read-Only Root Filesystem — The Yocto Project ® dev documentation
Yes, when wear leveling occurs, an increase in the bad block counter indicates that the NAND flash resources are depleting, necessitating immediate backup and replacement.