It really depends what you exactly want to do. If you need to be “in control” (CPU calculates stuff or something) between transfers, then it is probably hard to get lower with Linux.
However, if your use case allows you to send lots of messages in one batch without interactions in between, then you should be able to pool the transfers and send them down the stack in one batch.
The header file has some information on how to pack multiple transfers in a single message:
I would expect this to be already much faster by default. There also might be some optimization potential in the driver drivers/spi/spi-fsl-dspi.c…
If your application allows to batch transfers, then I am pretty sure you should be enable to achieve lower time between transfers.
However, if your application needs to do calculations between every transfer (closed loop style), then it will be much harder with Linux and the M4 approach may be worthwhile.
Thanks for that, @stefan.tx.
For the M4-side, I’m starting with the Toradex guide for FreeRTOS in M4 present in this link, at the “Linux” tab:
I’m seeing that it will need a work in io-muxing for the SPI signals, as presented in the pin_mux.c for the imx7.
And for the Linux-side using the A5, do you thing that would be possible to reduce even more the time-window between SPI transfers?
@jaski.tx managed to get a time-window of 70-80us (which I’m on the way to try to reproduce it here), but we would need as shorter as possible window.
Best,
Andre Curvello
Unfortunately, it is not possible to work with a “predictable” batch of messages, as the application works on demand with the other device, as you said, with interactions in between (each other).
So, I’ll reproduce the setup of yours to achieve the 70-80us time-window between SPI transfers, and I’d like to check with you guys if you could provide a base-code of SPI usage for M4 of VF61 (using SPI1 or SPI0 for example) to accelerate things here, I’d be very grateful for that.
If you could provide this base-code, could you tell a proximate date for that?
We currently have no plans to add driver support/create an example for DSPI to FreeRTOS. You might be able to reuse parts of the DSPI driver for eCos:
We do have examples for SPI on Colibri iMX7 Cortex-M4 core. Also the i.MX 7 HMP design is much better then Vybrids (e.g. allows hardware enforced isolation of peripherals). Did you consider using Colibri iMX7S instead of Colibri VF61?
@jaski.tx I managed to get a 70us delay between SPI transfers.
How did you managed to reduce it to around 50us?
i had DMA disabled. I can send you some screenshot today.
Hi @jaski.tx,
I would be very thankful for that.
And as for the PREEMPT mode setup for your Linux, is it set to PREEMPT VOLUNTARY?
Best,
Andre Curvello
Hi
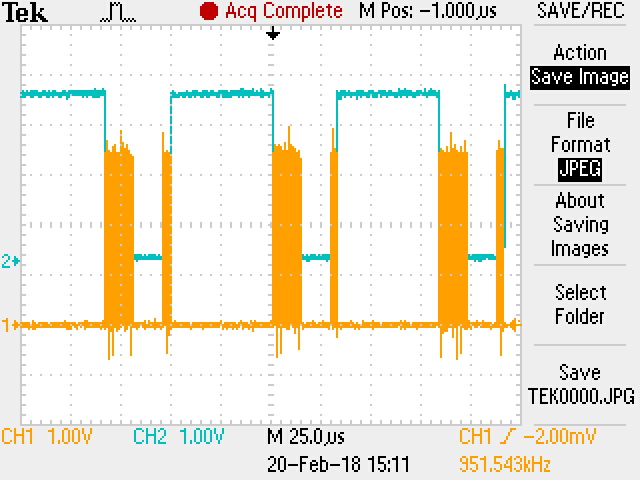
this is the image of the spi transfer without DMA.
As you can see, there is transfer every 50us. Due to missing DMA, the transfer is not continuous. I did not changed the PREEMPT settings, they are as the default Toradex images.
Ok, @jaski.tx!
So, checking here - colibri_vf_defconfig « configs « arm « arch - linux-toradex.git - Linux kernel for Apalis, Colibri and Verdin modules, the default config for PREEMPT is “CONFIG_PREEMPT_VOLUNTARY=y”.
I leaved that here, and I removed the DMA using the “/delete-property/dma-names;” in each SPI node.
Using that, I managed to get the 50us between SPI transfers, which is a good thing here!
Thanks for your support.
[upload|2+wmQO5+aJUXI8BAmhQsTws2U20=]
“But”, using 5 words in a row of a SPI transfer, I have this profile of transmission as follow attached, named “spi-transfer-5words.jpeg”.
[upload|0smIPO0n0j4U1sEC82so2PD49vg=]
And using 4 words, the whole SPI transfer is very reduced, see “spi-transfer-4words.jpeg”.
[upload|bZ72cP3zpoc69BVz/mPlLwZnAwU=]
There is a way to put all the “5 words” together, or this is a hardware characteristic of VF61?
hi,
I cannot see the images. I think, since the DMA is not enabled, the whole spi transfer is done differently. Can you try to put the priority of the transfer task higher and check if this change anything?
Hi @jaski.tx,
I’ve inserted the images in the reply, but for some reason they weren’t being displayed. See if they are now.
I think that it’s a issue regarding the DMA.
I tested it here with DMA enabled, and it sended the 5 16-bit words together, and with DMA disabled, it happened this way (4 words together +1).
So, we have this results for a SPI transmission of 5 16-bit words in 25 MHz:
- With DMA enabled - 5us in transmission - 70us in interval of transmissions = 75us total
- With DMA disabled - 20us in transmission - 50us in interval of tranmissions = 70us total.
The change is only in 5us 
For this example-test, the spi application is running in a loop doing the SPI transmission, with no other threads.
Best,
Andre Curvello
Hi andrecurvello,
I can see the images now.
- If you enable DMA, then the DMA setup will take time, thats why you have a bigger interval between two transmissions.
- If you disable DMA, then you don’t need to setup DMA, but data length per transfer is limited.
As stefan suggsted, you should consider using Colibri iMX7S instead of Colibri VF61.
Hi @jaski.tx,
That is not a option for this current project, as it is ready for production and some are being manufactured already.
We were working in the improvement of this communication between the VF61 and another module in the board.
The improvement using DMA and 70us between transfers resulted in a good timing for our application, but if that could be improved even more, it would be great to work in some scenarios were a quick response is needed.
It’s good that 70us fits your application. I think, further improvement is only possible with writing custom spi drivers or custom kernel modules.